Oracle Query Execution Logs Extraction and Source Code Prerequisites
This topic briefs about the Oracle assessment query execution logs and source code extraction prerequisites.
In This Topic:
Introduction
LeapLogic’s Assessment profiles existing inventory, identifies complexity, performs dependency analysis, and provides recommendations for migration to modern data platform.
Assessment checklist
Follow the steps in section 2, 3 to collect the required information for assessment.
Prerequisites
See the below prerequisites for the extraction of Oracle query execution logs.
- AWR should be up and running
- AWR retention should be greater than 1, example, if retention is 30, system retrieves 30 days of query logs
- TOPNSQL should be set to maximum. If it isn’t, we may not get all the SQL details
Limitation – SQL with < 10 seconds execution time will not show up in logs (Oracle default behavior)
SQL to check current AWR settings:
select * from dba_hist_wr_control
- AWR settings can be modified using the below command
dbms_workload_repository.modify_snapshot_settings(interval => 60,retention => 43200,topnsql =>’MAXIMUM’);
Follow the steps in section 3,4 to collect the required information for assessment.
Security Considerations and Disclaimer
The intention of this document is to export just the database objects and schema. LeapLogic does not need any kind of customer data for executing assessment or code transformation.
- The steps given in this document for exporting the required workloads does not alter or modify any data.
- It primarily consists of Select queries only.
- The required metadata is fetched from the system tables, not from the tables used in the customer’s environment.
Assessment Process
Use SQL Developer (Preferred) to export all your database objects and logs. Follow the below given steps to start exporting the workloads from your environment.
- Run the respective queries that you see in the subsequent sub-sections using SQL Developer.
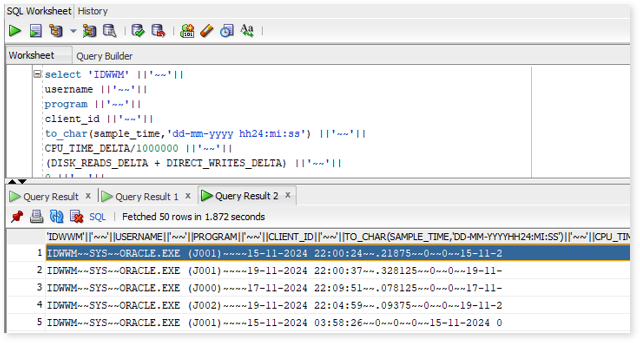
- Right-click on the result and choose “Export“.
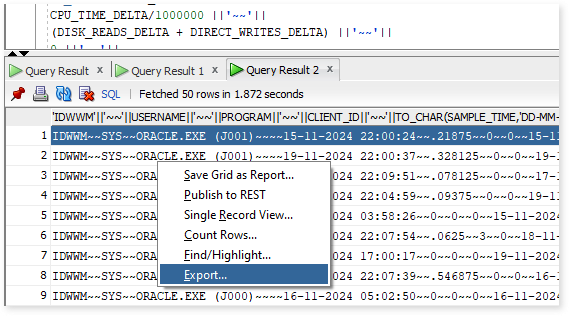
- In the Export wizard, choose CSV as the format.
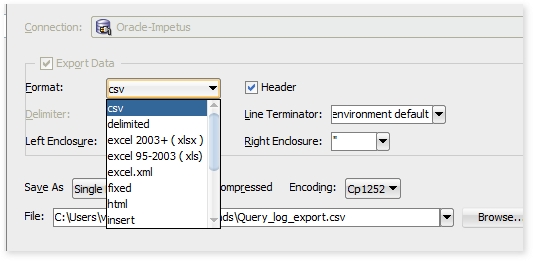
- Enable the compression, specify the file name and location for the export file.
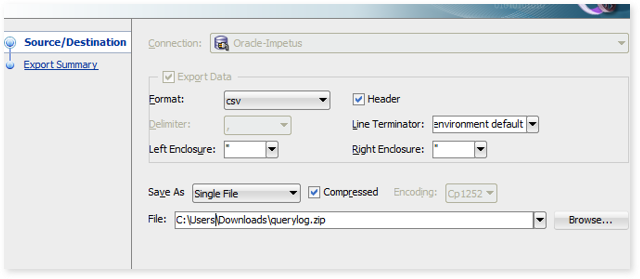
- Click “Next” and then “Finish” to export the query result to a compressed file.
This requires query log in a CSV format. It should be enabled on the data warehouse. The CSV file must have following columns (~~ separated file) retrieved from DBA_HIST* tables.
Filler~~UserName~~Progam~~ClientID~~StartTime~~CPUTime~~TotalIOCount~~ParserCPUTime~~FirstRespTime~~FirstStepTime~~ProcID~~QueryID~~MaxCPUTime~~MaxIO~~totalCPU~~totalIO~~Query_Execution_Time~~SchemaNAME ~~SQLTYPE~~SQLTEXTINFO~~ execution_frequency
There are two options for query execution log extraction. The preferred one is GUI based. In case, there’re any problems encountered with the GUI-based option, then PL/SQL-based option can be used.
Option 1: GUI Based
Preferably, use a GUI tool such as SQL Developer or Toad etc. for gathering the log information from Oracle. All the environment specific variables are highlighted in the document.
The SQL query to collect the required log information is as given below.
select ‘IDWWM’ ||’~~’||
username ||’~~’||
program ||’~~’||
client_id ||’~~’||
to_char(sample_time,’dd-mm-yyyy hh24:mi:ss’) ||’~~’||
CPU_TIME_DELTA/1000000 ||’~~’||
(DISK_READS_DELTA + DIRECT_WRITES_DELTA) ||’~~’||
0 ||’~~’||
to_char(sample_time + ELAPSED_TIME_DELTA/86400000000,’dd-mm-yyyy hh24:mi:ss’) ||’~~’||
to_char(sample_time,’dd-mm-yyyy hh24:mi:ss’) ||’~~’||
0 ||’~~’||
a.sql_id ||’~~’||
CPU_TIME_DELTA/1000000 ||’~~’||
(DISK_READS_DELTA + DIRECT_WRITES_DELTA) ||’~~’||
sum(CPU_TIME_DELTA/1000000) over (partition by trunc(sample_time)) ||’~~’||
sum(DISK_READS_DELTA + DIRECT_WRITES_DELTA) over(partition by trunc(sample_time)) ||’~~’||
ELAPSED_TIME_DELTA/1000000 ||’~~’||
parsing_schema_name ||’~~’||
v.command_name ||’~~’||
sql_text ||’~~’||
executions_delta
from
(
select t.*,row_number() over(partition by snap_id,sql_id order by sample_time) as rn from dba_hist_active_sess_history t
where cast( sample_time as date) between to_date(’15-11-2024′, ‘dd-mm-yyyy’) and to_date(’20-11-2024′, ‘dd-mm-yyyy’)
)a,
dba_hist_sqlstat b,
dba_hist_sqltext c,
dba_users d,
v$sqlcommand v
where
a.sql_id = b.sql_id
and a.snap_id = b.snap_id
and b.sql_id = c.sql_id
and d.user_id = a.user_id
and a.rn = 1
and c.command_type=v.command_type
order by a.sql_id;
Option 2: PL/SQL Based
In case of any problem with the GUI-based option, execute the attached PL/SQL block.
Hardware Configuration
The details of hardware configuration are required for the calculation of total CPU utilization. Please provide the following details.
- Oracle series and specs (Cores, RAM, HDD/SDD)
- Number of nodes in the cluster (RAC)
Software Version
This query provides the software version in use. Save its results in a CSV file.
Database Objects
This query provides the count of database objects in use. Save its results in a CSV file.
select owner,object_type,count(object_name) from dba_objects group by owner,object_type;
Database Volume
This query provides the database volume greater than 10 GB in use. Save its results in a CSV file.
select owner,sum(bytes)/1024/1024/1024 from dba_segments group by owner order by 2 desc;
High Data Volume Tables
This query provides result for tables with high data volume. Save its results in a CSV file. This SQL will collect databases with volume equal or above 10 GB.
select
a.owner,
a.segment_name as table_name,
a.tab_size_gb,
b.partitioning_type,
b.partition_count,
c.num_rows
from
(
select owner,segment_name,sum(bytes)/1024/1024/1024 tab_size_gb from dba_segments where segment_type=’TABLE’
group by owner,segment_name
)a
left outer join dba_part_tables b
on a.owner = b.owner
and a.segment_name = b.table_name
left outer join dba_tables c
on a.owner = c.owner and a.segment_name = c.table_name
Users
This query provides the total number of users. Save its results in a CSV file.
select username from dba_users
Data for Partitioning / Bucketing
This query extracts table size and column details to be utilized for partitioning and bucketing recommendations. Save the result in a CSV file.
SELECT Sys_context(‘userenv’, ‘db_name’) AS DATABASE_NAME,
DBA_TAB.table_name AS Table_Name,
Sum(us.bytes)AS TABLE_SIZE_BYTES,
Nvl(ut.num_rows, 0) AS NUM_ROWS,
DBA_TAB.column_name AS Column_Name,
Nvl(DBA_TAB.num_distinct, 0) AS num_unique_val
FROM dba_tab_columns DBA_TAB
JOIN user_segments US
ON ( DBA_TAB.table_name = us.segment_name )
JOIN user_tables ut
ON( DBA_TAB.table_name = ut.table_name )
WHERE owner NOT IN ( ‘ANONYMOUS’, ‘APEX_040200’, ‘APEX_PUBLIC_USER’,
‘APPQOSSYS’,
‘AUDSYS’, ‘BI’, ‘CTXSYS’, ‘DBSNMP’,
‘DIP’, ‘DVF’, ‘DVSYS’, ‘EXFSYS’,
‘FLOWS_FILES’, ‘GSMADMIN_INTERNAL’, ‘GSMCATUSER’,
‘GSMUSER’,
‘HR’, ‘IX’, ‘LBACSYS’, ‘MDDATA’,
‘MDSYS’, ‘OE’, ‘ORACLE_OCM’, ‘ORDDATA’,
‘ORDPLUGINS’, ‘ORDSYS’, ‘OUTLN’, ‘PM’,
‘SCOTT’, ‘SH’, ‘SI_INFORMTN_SCHEMA’,
‘SPATIAL_CSW_ADMIN_USR’,
‘SPATIAL_WFS_ADMIN_USR’, ‘SYS’, ‘SYSBACKUP’, ‘SYSDG’,
‘SYSKM’, ‘SYSTEM’, ‘WMSYS’, ‘XDB’,
‘SYSMAN’, ‘RMAN’, ‘RMAN_BACKUP’, ‘OLAPSYS’,
‘APEX_030200’, ‘OWBSYS’ )
GROUP BY Sys_context(‘userenv’, ‘db_name’),
DBA_TAB.table_name,
Nvl(DBA_TAB.num_distinct, 0),
Nvl(ut.num_rows, 0),
DBA_TAB.column_name;
Database Objects
There are two options for extracting database objects like tables, views, and procedures. The first option is to use the Oracle SQL Developer tool. The second option is to use a Java-based utility.
DDL Export – Using SQL Developer
Oracle SQL Developer is an integrated development environment for working with SQL in Oracle databases. You can download it as either an installer or zip file from the official website.
Follow these steps once SQL Developer is set up.
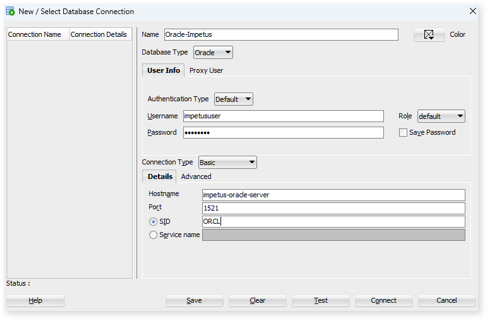
Connect to Oracle using SQL Developer
Connect to the server using SQL Developer by entering details such as the hostname/IP, username, password, port, and SID. Test the connection and save it.
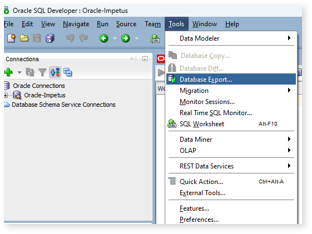
After connecting to Oracle, navigate to Tools and select the Database Export option.
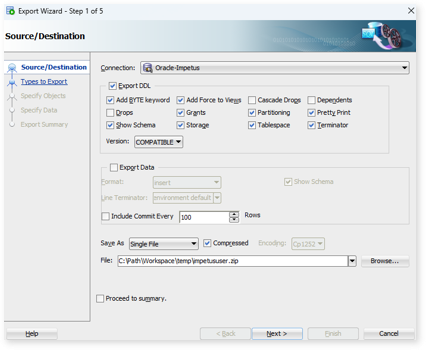
On the Source/Destination screen:
- Select the Oracle connection saved in the first step.
- Check only the Export DDL option and uncheck the Export Data option.
- Enable the Compression option.
- Specify the file path and file name.
- Retain all the default settings.
- Click Next.
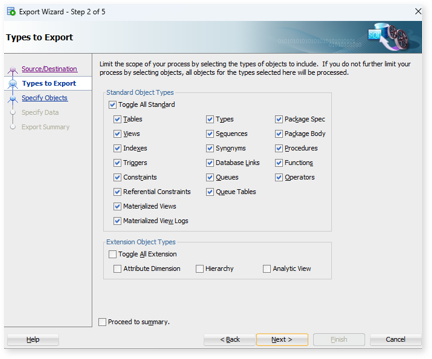
On the Types to Export screen, retain all the default options and click Next.
On the Specify Objects screen:
- Click on More and ensure the Type is set to ALL OBJECTS.
- Click Next.
Finally, you will see the Export Summary. Click Finish to export the DDLs.
DDL Export – Using Java Utility
Another option is to export database objects using the Java Utility. Click here to download. This utility is compatible with both Linux and Windows environments.
Windows Environment
After downloading the utility, extract the zip file and navigate to the bin folder. Modify the highlighted variables in the schema_extract.bat file.
set IDW_WMG_HOME=C:\\Path\\Oracle_code_extractor
set IDW_WMG_LOG=%IDW_WMG_HOME%\\logs
set IDW_WMG_CONF=%IDW_WMG_HOME%\\conf
set JAVA_HOME=C:\\”Program Files”\\Java\\jdk1.8.0_121
%JAVA_HOME%\\bin\\java -Xms512m -Xmx1024m -Xmn128m -Xss256k -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=512m -XX:+UseParallelOldGC -XX:LargePageSizeInBytes=4m -XX:+PrintGCDetails -XX:+UseCompressedOops -XX:+PrintGCDateStamps -verbosegc -Xloggc:%IDW_WMG_HOME%\\run/gc_schema_ex.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%IDW_WMG_HOME%\\run\\ -cp “%IDW_WMG_HOME%\\lib\\*” com.impetus.idw.wmg.db.core.code.extract.EDWCodeExtractor “oracle_assessment” “%IDW_WMG_HOME%\\temp\\” “oracle” “SID” “HOST” “PORT” “Username” “Password” “Schema1,schema2“
After making the required changes, double-click the schema_extract.bat file. The utility will begin extracting the database objects for the specified schema, saving them to the temp folder.
Linux Environment
After downloading the utility, extract the zip file and navigate to the bin folder. Modify the highlighted variables in the schema_extract.sh file.
export IDW_WMG_HOME=”$(cd “$(dirname “$0″)/../”; pwd)”;
export IDW_WMG_LOG=”${IDW_WMG_HOME}/logs/”
export IDW_WMG_CONF=”${IDW_WMG_HOME}/conf/”
export JAVA_HOME=“/opt/jdk1.8.0_181”
${JAVA_HOME}/bin/java -Xms512m -Xmx1024m -Xmn128m -Xss256k -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=512m -XX:+UseParallelOldGC -XX:LargePageSizeInBytes=4m -XX:+PrintGCDetails -XX:+UseCompressedOops -XX:+PrintGCDateStamps -verbosegc -Xloggc:${IDW_WMG_HOME}/run/gc_schema_ex.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${IDW_WMG_HOME}/run/ -cp :${IDW_WMG_HOME}/lib/* com.impetus.idw.wmg.db.core.code.extract.EDWCodeExtractor “oracle_assessment” “${IDW_WMG_HOME}/temp/” “oracle” “${sid}” “${IP}” “1521” “${username}” “${pwd}” “${SchemaName1},{SchemaName2}…”
After making the required changes, execute the schema_extract.sh file.
The utility will begin extracting the database objects for the specified schema, saving them to the temp folder.
Source Code Assessment
Provide the below active or in-scope Oracle source code artifacts as applicable in the migration scope.
|
Code Artifact |
Criticality |
Remarks |
|
Orchestration Scripts (Control-M / Autosys / Cron etc.) |
Must |
To identify interdependencies across scheduler scripts / jobs, queries, and dependent workloads |
|
Procedures / Functions |
Must |
To identify workload complexity, query count, effort estimation and technical debt |
|
Packages |
Must |
To identify PL/SQL count, complexity and effort estimations |
|
Views |
Must |
To identify view complexity, patterns and effort estimations |
|
Shell Scripts |
Must |
To identify count, dependencies, SQL queries and PL/SQL, logics (example email, notification etc.) and effort estimations |
|
DDL |
Must |
To identify column usage, and provide recommendation on column level lineage, and query optimization on the target system |
|
DML / SQL Files |
Must |
To identify count, dependencies, SQL queries and effort estimations |
|
CTL Files |
Must |
To identify source data type and formats example Delimiters, JSON etc. |
|
Sequences |
Must |
To estimate efforts, example, custom sequence |
|
Indexes |
Could |
To recommend partitioning / bucketing strategy (depends on the target of choice) |