Optimization
This topic provides a detailed examination of the optimization process. LeapLogic’s intelligent grammar engine identifies optimization opportunities at schema, and orchestration levels.
In this Topic:
Schema
Schema refers to how data is organized within a database. Optimizing schema is critical based on the complexity of the queries in the schema. By interpreting the input files, DDL files help in retrieving schema-level information and generating corresponding recommendations for the target.
Schema optimization opportunities include:
- Increasing parallelism
- Joins and Update/Delete/Merge operations can be optimized
Target as Databricks
If the target is Databricks, the schema optimization is based on liquid clustering. Liquid clustering organizes data based on the columns specified in the Cluster By key.

- Entity Name: Name of the entity.
- Cluster By: Column name specified here is used to organize data within the table.
- Frequency of Use: Displays the frequency of table used.
- Primary Key: To identify unique row in the table. It will not accept NULL values.
- Tune Based on Workload: If a Delta table experiences frequent MERGE, UPDATE, or DELETE operation, then this helps to tune file sizes for rewrites by setting the table property delta.tuneFileSizesForRewrites.
- Tune Based on Table Sizes: Helps to configure the target file size based on source table size. For example, for 1 TB table size, the size of the target file should be 256 MB; for 10 TB, it should be 1 GB and likewise.
- Compaction (bin-packing): Delta Lake on Databricks improves the speed of read queries from a table by coalescing small files into larger ones.
- Data Source: Provides data source details.
- Entity Type: Displays the type of entities.
- Transactional: Displays the number of data flow components that are used to perform sorting, merging, data cleansing and so on.
- Data Volume: Displays the quantity of data.
- Unique Key: To identify records in a table.
- Details: Provides additional details about the entities.
Target as Redshift
If the target is Amazon Redshift, the schema optimization strategies are Sortkey, Distkey, Compression encoding, and Analyze command.

- Entity Name: Name of the entity.
- Sortkey: Redshift selects the best sort key based on the table usage. It defines the data storage method for a 1MB disc block. Sorting enables efficient handling of range-restricted predicates. The min and max values for each block are stored in the metadata.
- Distkey: DIST Keys (Redshift Distribution Keys) determine where data is stored in Redshift cluster nodes.
- Collect Table Stats: Run ANALYZE command to collect statistics of tables that are used in the following types of queries:
- Table used together most frequently.
- Tables on which WHERE predicates are applied.
- Tables with low cardinality columns (duplicate rows)
- Data Source: Provides data source details.
- Entity Type: Displays the type of entities.
- Frequency of Use: Displays the frequency of table used.
- Transactional: Displays the number of data flow components that are used to perform sorting, merging, data cleansing and so on.
- Data Volume: Displays the quantity of data.
- Primary Key: Displays the Primary Key which identifies each row in the table. It does not accept NULL values.
- Unique Key: Displays the Unique key. The unique key ensures that the values are unique across all records in the table.
- Details: Provides additional details about the entities.
Target as AWS/ Snowflake/ GCP
If the target is AWS/ Snowflake/ GCP, the schema optimization is performed using the Partition By key.

- Entity Name: Name of the entity.
- Partition by: Divides the table data into smaller, separate partitions for efficient data retrieval.
- Data Source: Provides data source details.
- Entity Type: Displays the type of each entity.
- Frequency of Use: Displays the frequency of table used.
- Transactional: Displays the number of data flow components that are used to perform sorting, merging, data cleansing and so on.
- Data Volume: Displays the quantity of data.
- Primary Key: Displays the Primary Key which identifies each row in the table. It does not accept NULL values.
- Unique Key: Displays the Unique key. The unique key ensures that the values are unique across all records in the table.
- Details: Provides additional details about the entities.
Target as Hive/ Spark
If the target is Hive/ Spark, the schema optimization strategies are Partitioning, Bucketing, and Clustering. For schema optimization, determining the right partitioning strategy helps to logically divide the data into different directories for efficient data retrieval.
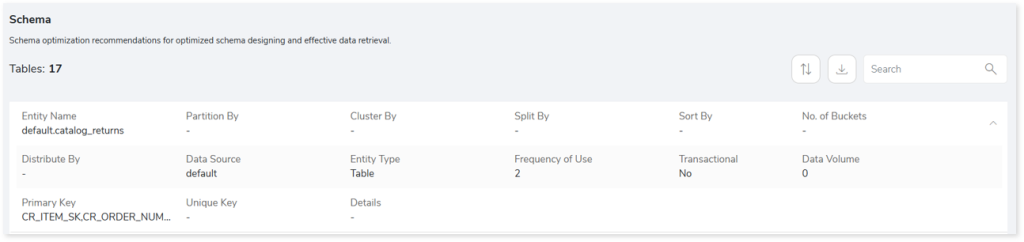
- Entity Name: Name of the entity.
- Partition By: Divides the table data into smaller, separate partitions for efficient data retrieval.
- Cluster By: Groups data into different files for efficient data retrieval.
- Split By: Splits data based on the selected column.
- Sort By: Displays the Sort By key, which is used to arrange the data.
- No. of Buckets: Displays the number of buckets used to divide data during clustering.
- Distributed By: Displays details of columns used for distribution.
- Data Source: Provides data source details.
- Entity Type: Displays the type of entities.
- Frequency of Use: Displays the frequency of table used.
- Transactional: Displays the number of data flow components that are used to perform sorting, merging, data cleansing and so on.
- Data Volume: Displays the quantity of data.
- Primary Key: Displays the Primary Key which identifies each row in the table. It does not accept NULL values.
- Unique Key: Displays the Unique key. The unique key ensures that the values are unique across all records in the table.
- Details: Provides additional details about the entities.
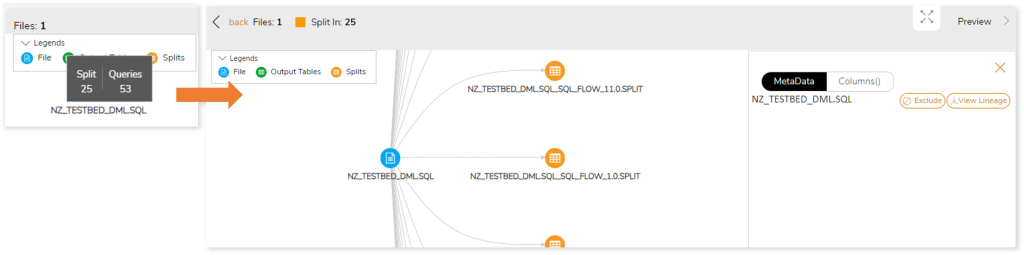
Orchestration
This section details data splits and recommends the maximum possible number of queries that can be executed in parallel for orchestration optimization.
Orchestration helps to easily manage workflows to accomplish a specific task. In orchestration, the independent queries of each file are divided into different splits that run in parallel to increase efficiency.
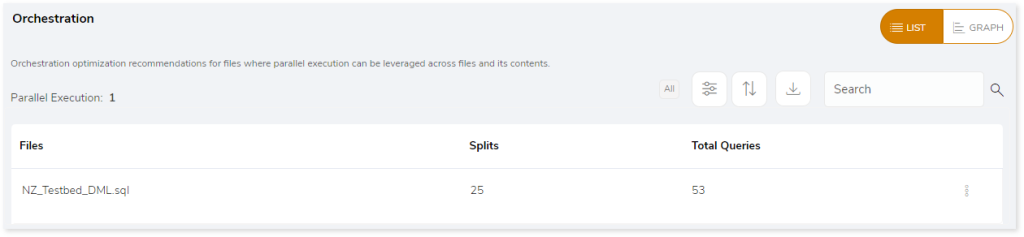
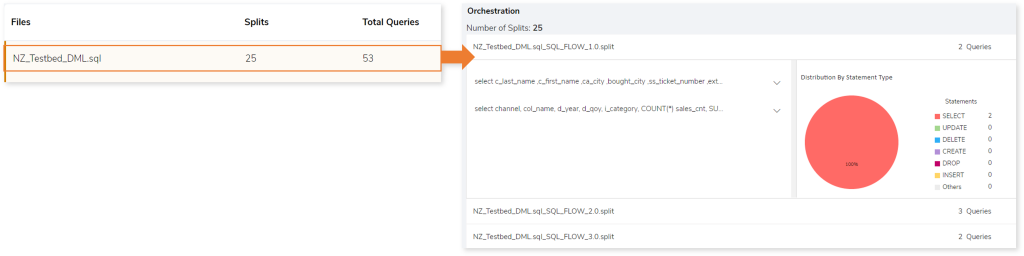
As per the above figure, the file contains 53 queries, which are separated into 25 splits based on the query dependency. By running these 25 splits in parallel, we can enhance the performance and execution time.
To get more insight, navigate to Files‘ row > Number of splits row, you can view the query and graphical distribution of the statement type.
Orchestration’s GRAPH displays the dependencies between files, splits, and output tables. To get the dependency information regarding splits and queries, choose the preferred node.