Configuring Execution Stage
The Execution stages allow transformed queries to be executed on target platforms. In the integrated pipeline, all the input data is automatically fetched from the previous stage (Transformation stage) for execution. Execution cannot be performed or fail if the Transformation stage doesn’t succeed or doesn’t reach 100%. Therefore, make sure that the Transformation stage is successful before proceeding to the Execution stage.
In this Topic:
Overview
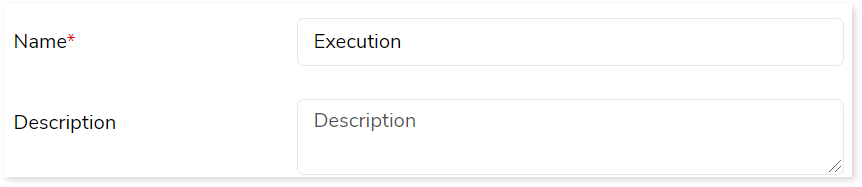
In this section, you can customize the Execution stage’s name and give a suitable description as required. By default, Execution is provided in the Name field. Provide a relevant name and description in a way that clarifies the purpose and scope of the Execution stage.
Transform
In this section, you need to provide the target data source, input type, execution bundle, source type, and the number of parallel execution details.
To configure the Execution stage, follow the below steps:
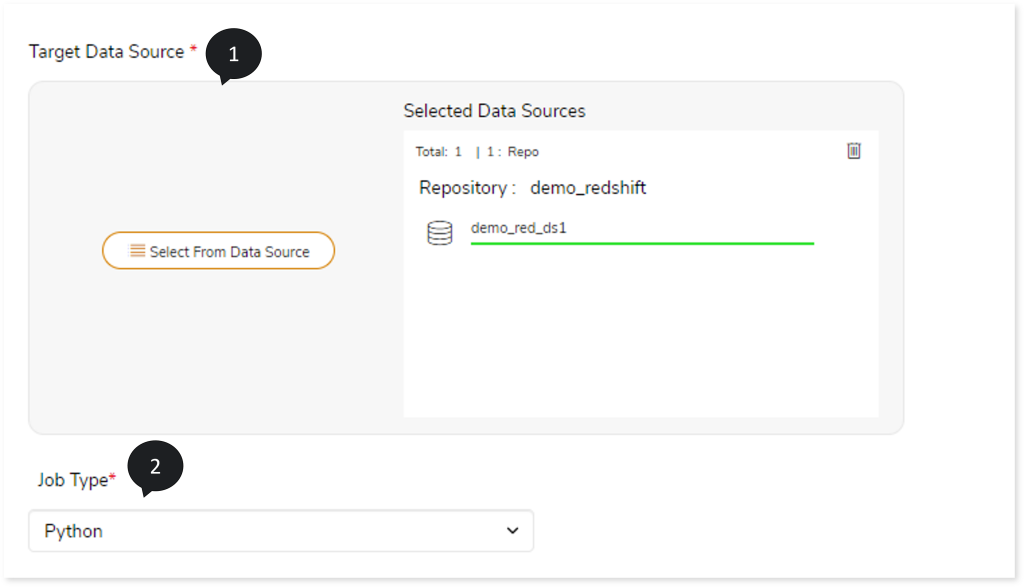
- In Target Data Source, upload the target data source to execute the transformed queries. To do so, follow the below steps:
- Click Target Data Source.
- Choose repository.
- Select data source.
- Click
 to save the target data source.
to save the target data source.
- In Job Type, select the job type such as Java, or Scala, or Python that you want to execute.
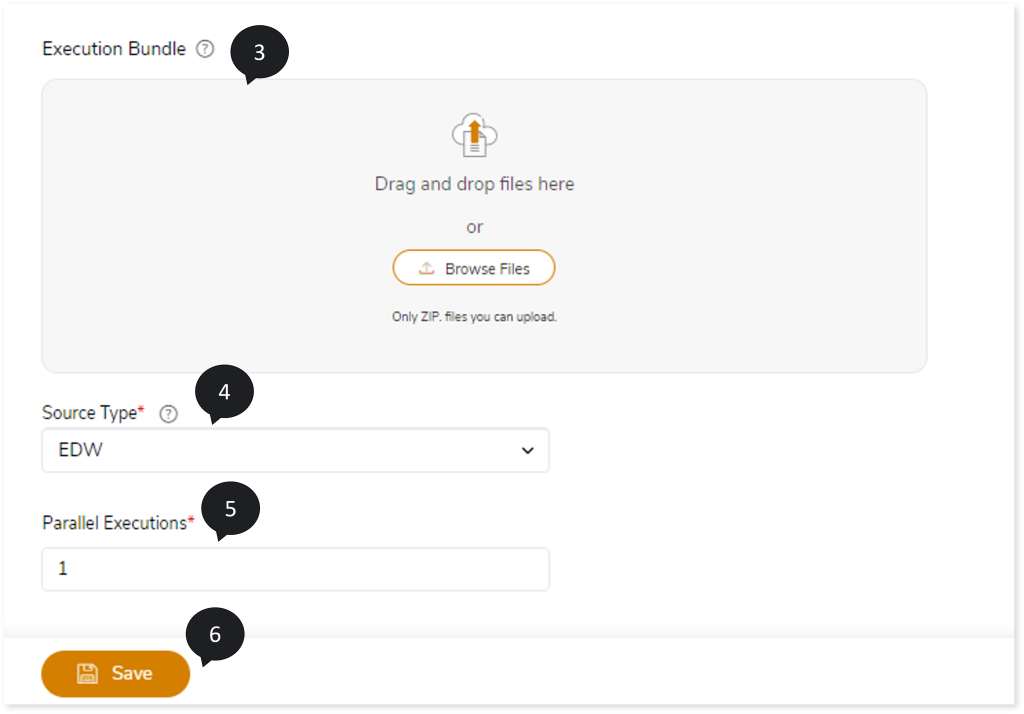
- In Execution Bundle, upload the script (zip format) that needs to be executed on the selected target.
- In Source Type , select the type of source script that needs to be executed, such as EDW, DataStage ETL Script, Informatica ETL Script, AbInitio ETL Script, or SSIS ETL Script.
- In Parallel Executions, specify the number of jobs that should be executed in parallel.
- Click Save to save the Execution stage. When this stage is saved successfully, the system displays an alerting snackbar pop-up to notify the success message.

- Click
 to execute the integrated or standalone pipeline. The pipeline listing page opens that displays the pipeline status as Running state. When execution is successfully completed the status changes to Success .
to execute the integrated or standalone pipeline. The pipeline listing page opens that displays the pipeline status as Running state. When execution is successfully completed the status changes to Success .
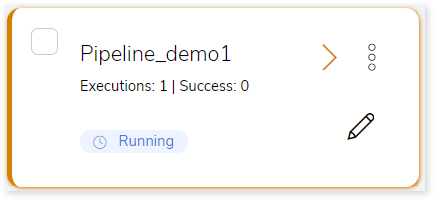
- Click on your pipeline card to see reports.
To view the Execution Stage report, visit Execution Report.
Output
The result of this stage is the execution of the transformed queries on the target platform. For instance, a query with a CREATE statement creates the required table in the target schema. Similarly, a query with an INSERT statement would ingests data into the specified target tables. You can view the report from the pipeline listing after the execution of this stage.
You can configure the output status of this stage if the transformation is not successful. By default, the output configuration is set to Error if the stage is not 100% or that can be configured to Continue, Stop, and Pause as required.

Next:
Configuring ETL Conversion