Highlights
The highlights section gives you a high-level overview of your assessment summary of the analytics performed on the selected workloads. It includes a graphical depiction of the analyzed workloads, insights, and recommendations.
In this Topic:
Enterprise Data Warehouse (EDW)
Recommendations
This section provides a snapshot of recommendations generated by the system as per the recommendation settings provided while creating the assessment. It recommends the number of files, jobs, queries, and entities that should be migrated. It also suggests the target platform as per your enterprise’s needs.

Files
This section gives a comprehensive recommendation summary of the analyzed files based on the key resource utilization metrics. It displays the total number of files, used files, unused files, used and unused queries. In addition, it offers insights into the complexity of used and unused queries.
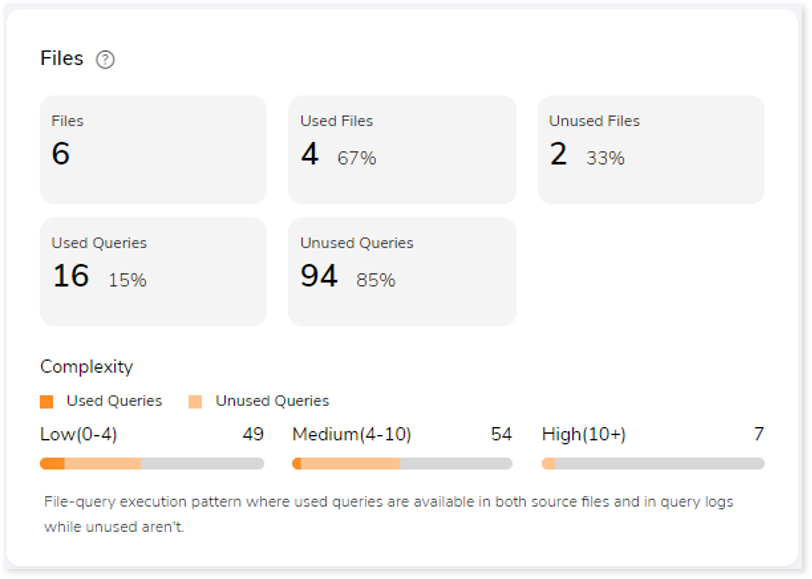
- Files: The total number of files available in the source file.
- Used Files: Displays the number of files where used queries are available in both DML scripts and Execution logs.
- Unused Files: Displays the number of files where used queries are not available in both DML scripts and Execution logs.
- Used Queries: Displays the number of queries that are used in both DML scripts and Execution logs.
- Unused Queries: Displays the number of queries that are used in DML scripts but not in Execution logs.
Orchestration Inventory
This section provides orchestration details including the total number of job input files, jobs, files used from those jobs and so on. A job is a set of tasks that control the system for scheduling, monitoring, and reporting.
Job types include schedulers or orchestration scripts, like:
- AutoSys: AutoSys is an automated job control system designed to schedule tasks. You can create jobs in Autosys as JIL (Job Information Language) format.
- Control-M: Control-M is a workflow orchestration solution by which you can manage workflow for data and applications on-premises or in the cloud.
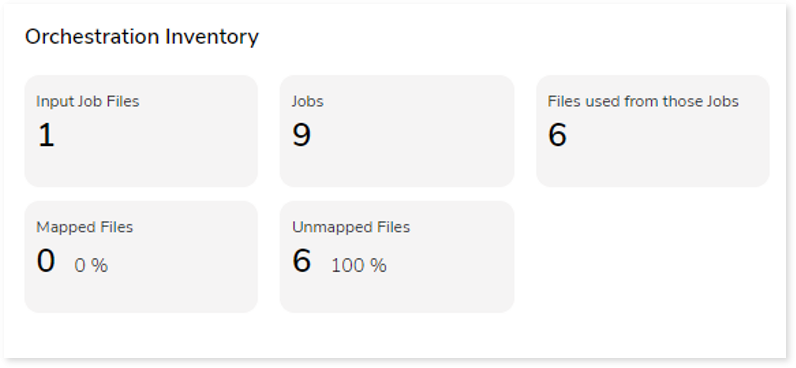
- Input Job Files: Total number of job files.
- Jobs: A job is a set of tasks that control the system for scheduling, monitoring, and reporting. It can be in the form of any command, file, or script.
- Files used from those jobs: Displays the number of DML files that are called by the Job scripts.
- Mapped Files: If the jobs and input source files are the same and can be mapped, they are referred to as mapped files.
- Unmapped Files: If the jobs and input source files are different and unable to map, they are referred to as unmapped files.
Queries
It displays a synopsis of the analyzed queries with information about unique queries, unique pattern queries as well as analyzed and unanalyzed queries.
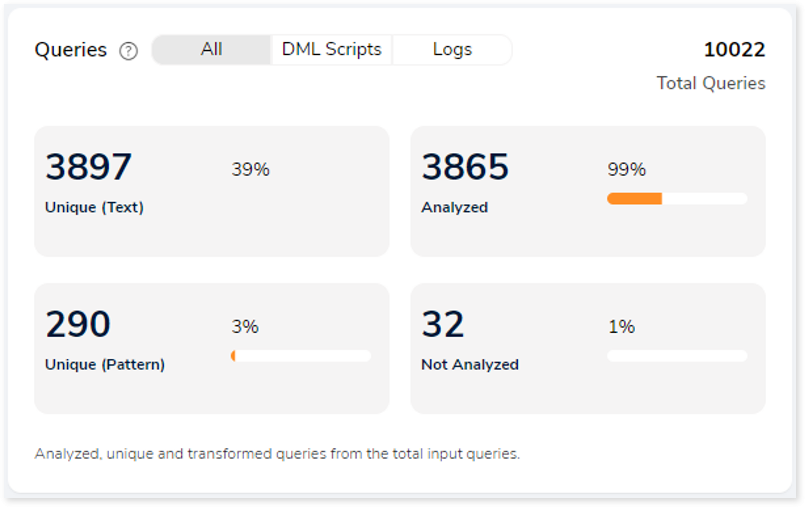
- Unique (Text): Duplicate queries are eliminated, and solitary queries are identified.
- Unique (Pattern): Identify the distinct query structures but the query structure’s values may change.
- Analyzed: Queries that meet the analysis criteria are shown.
- Not Analyzed: Queries that did not meet the analysis criteria are displayed here.
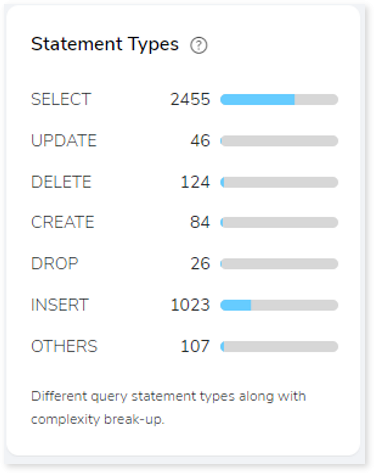
Statement Types
This section displays a summary of analyzed queries based on the query distribution sorted by the different query statement types in the input source file. Moreover, it displays a visual representation of the complexity breakdown across various statement types.
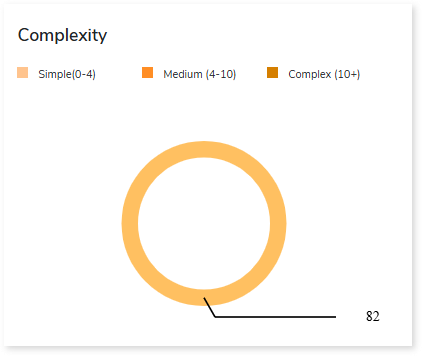
Complexity
This section provides a summarized graphical representation of queries’ complexity that helps in making different decisions, including budget estimation.
| Complexity Type | Complexity Range | Description |
| Low | 0-4 | Handled directly by the tool, it requires no manual effort. |
| Medium | 4-10 | Most of the queries can be converted directly by the tool, and some require minimum manual effort. |
| High | 10+ | Complexity is high and requires more manual effort to handle. |
Entities
This section provides a synopsis of the analyzed entities with information regarding the Tables and Views in the source file.
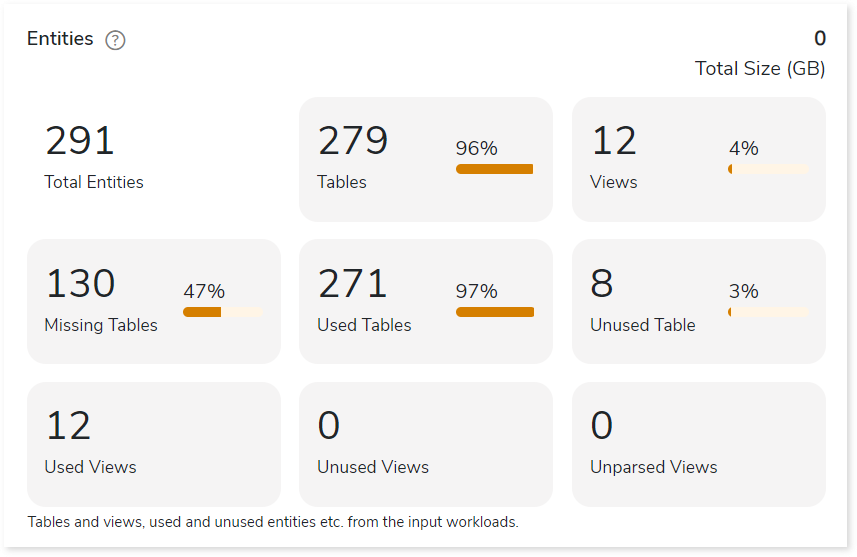
- Tables: Displays number of tables.
- Views: Displays number of views.
- Missing Tables: Tables which are used in DML scripts/ query logs, but no DDL scripts are associated with them.
- Used Tables: Tables which are used in DML scripts/ query logs.
- Unused Tables: Tables which are used in DDL scripts but not used in DML scripts/ query logs.
- Used Views: Displays the number of used views.
- Unused Views: Displays the number of unused views.
- Unparsed Views: Displays the number of unparsed views.
Entity Usage Type
This section provides information about the analyzed entities sorted by different entity usage types.
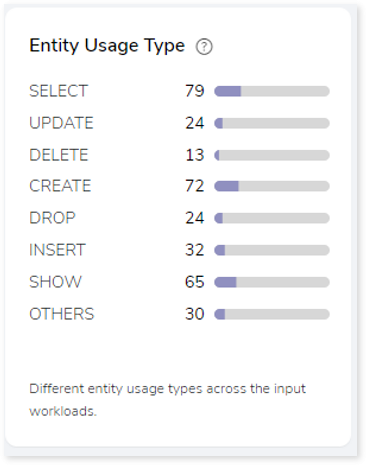
Table Type
This section provides summary of queries segregated by the break-up of table types. Table types are categorized according to the different statement types available in the input workload.
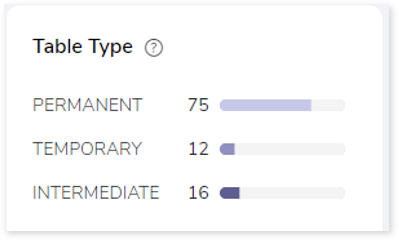
- Permanent: In DML, if the encountered statement types such as READ, UPDATE, and INSERT are considered permanent tables. For instance, tables that are created and perform actions but are not deleted are permanent tables.
- Intermediate: If the statement type CREATE is encountered, it refers to an intermediate table, or whenever a table is created and no actions are being performed, it is considered an intermediate table.
- Temporary: If the statement type CREATE and DROP are encountered, they refer to a temporary table. In other words, a table that is created and then deleted is considered a temporary table.
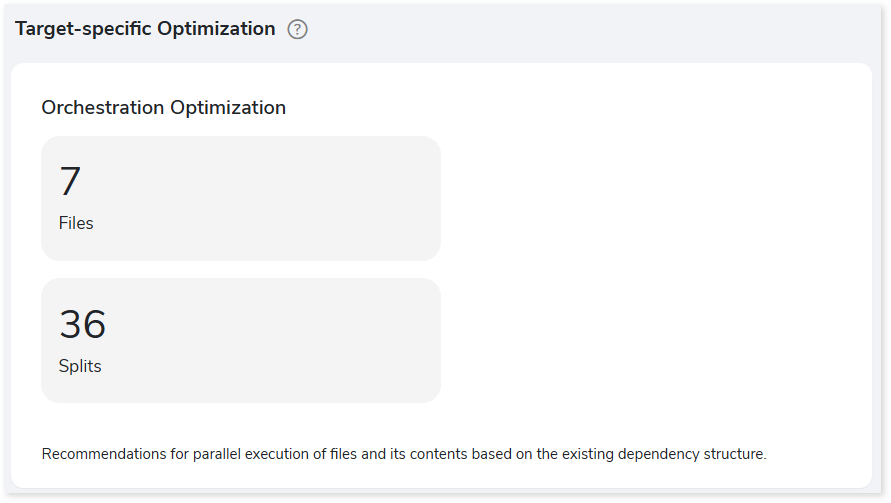
Target-specific Optimization
This section provides target optimization recommendations at the schema, and orchestration levels. Schema Optimization focuses on efficient schema design and effective data retrieval. Orchestration Optimization provides information about the parallel execution of files based on their dependency structure.
Resource Utilization
Productivity depends on the efficient use of resources. Resource utilization measures CPU utilization and I/O utilization over an available time.
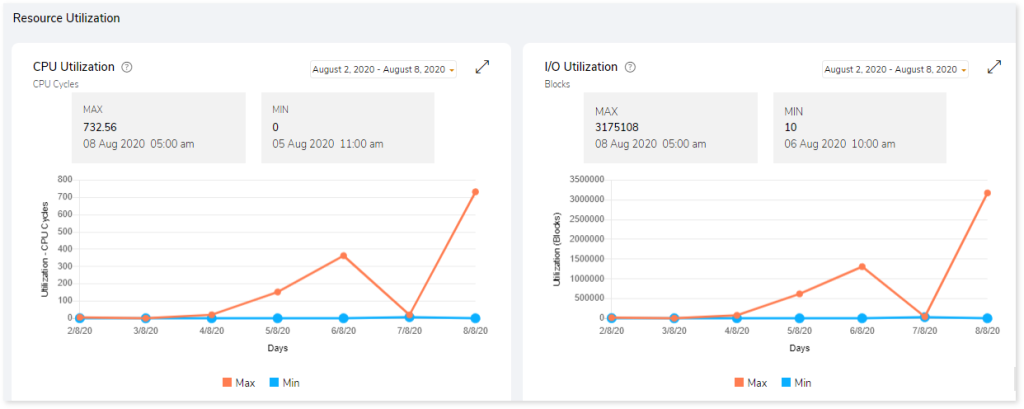
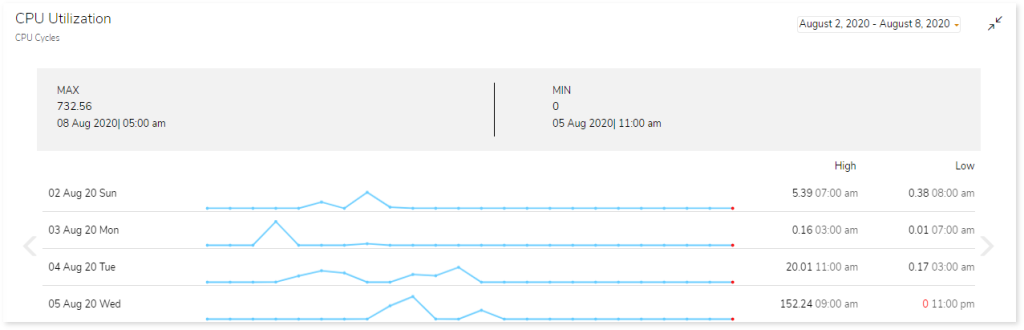
- CPU Utilization: CPU utilization refers to the amount of work the CPU handles. It shows the trend of CPU utilization across the selected or default timeframe.
- I/O Utilization: The amount of input and output processes over a specified time period is called I/O utilization. It shows the trend of I/O utilization across the selected or default timeframe.
Actions you can perform:
- Change the time duration by choosing the start and end date from the date card.
- To get a full-screen view of the graph, click
 .
.
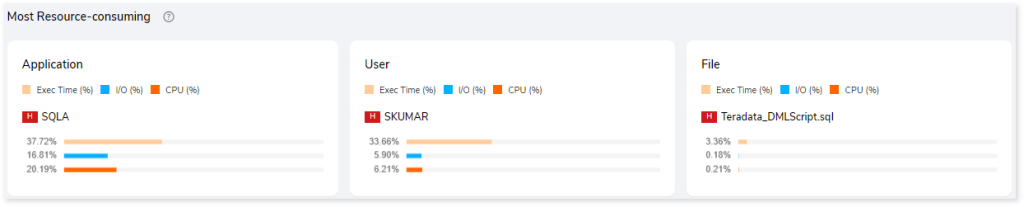
Most Resource-consuming
This section highlights the most resource-consuming/resource-utilizing application, user, and file.
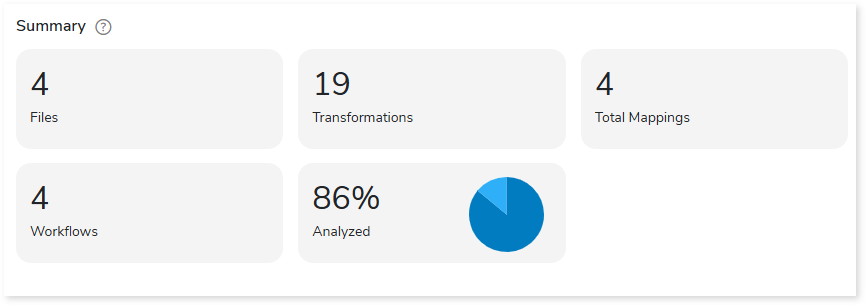
Summary
This section illustrates the input informatica graphs that were analyzed throughout the various workflows and components. Here, you can see the number of files, transformations, mappings and workflows as well as the analyzed percentage of the workloads.
Scheduler
Schedulers monitor and execute tasks or jobs at a specific time.
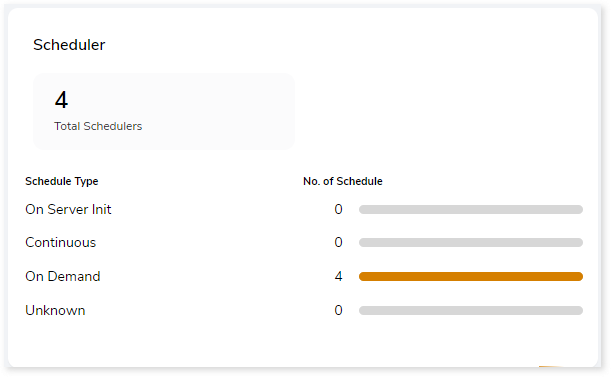
- On Server Init: The jobs are triggered based on the availability of the server.
- Continuous: Jobs that are continuously executed based on a scheduled time.
- On Demand: Jobs that are triggered manually for execution.
- Unknown: Jobs that do not belong to the above categories.
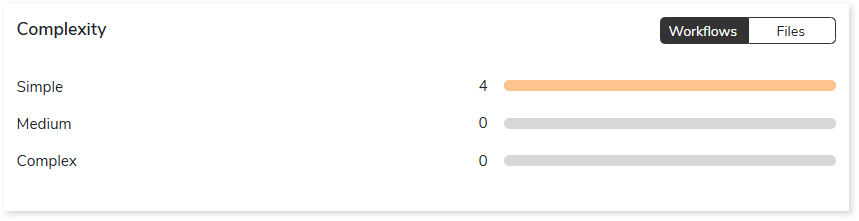
Complexity
This section provides a summarized graphical representation of the classification of Informatica files and workflows based on a detailed complexity assessment. This information is required to make different decisions, including migration planning, estimating budget etc.
BI Report
Summary
This section illustrates the input IBM Cognos scripts that were analyzed across the various elements. Here, you can see the number of files, packages, reports, pages, queries, visualizations, and more.
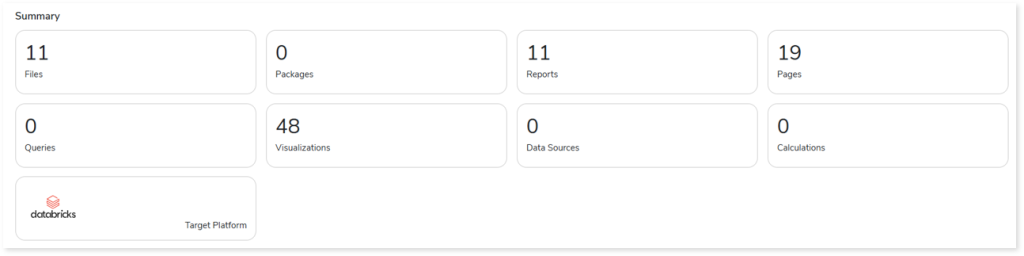
- Files: Displays the total number of source files.
- Packages: Displays the total number of packages in the source files. Packages are subsets of data models that provide specific data for reports.
- Reports: Displays the number of reports in the file.
- Pages: Displays the number of pages present in the reports.
- Queries: Displays the number of queries.
- Visualizations: Displays the number of visuals such as pie charts, heat maps, clustered column graphs, and more from reports.
- Data Sources: Displays the number of data sources from the data model.
- Calculations: Displays the number of calculations present in the reports.
- Target Platform: Displays the name of the target platform.
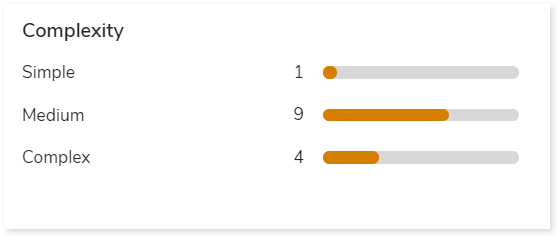
Complexity
This section provides a summarized graphical representation of the complexity of reports that helps in making different decisions, including budget estimation.
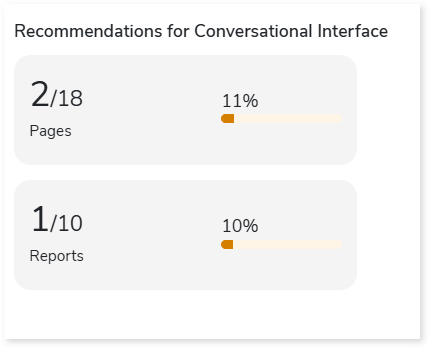
Recommendations for Conversational Interface
This section displays recommendations based on hierarchical structure for different report elements such as pages and reports. These insights help optimize scope and cost.
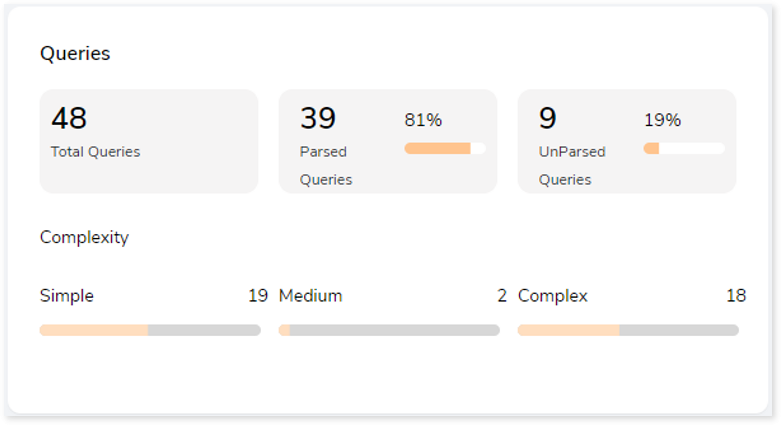
Queries
It displays a synopsis of the analyzed queries with information about parsed and unparsed queries as well as the complexity of queries.
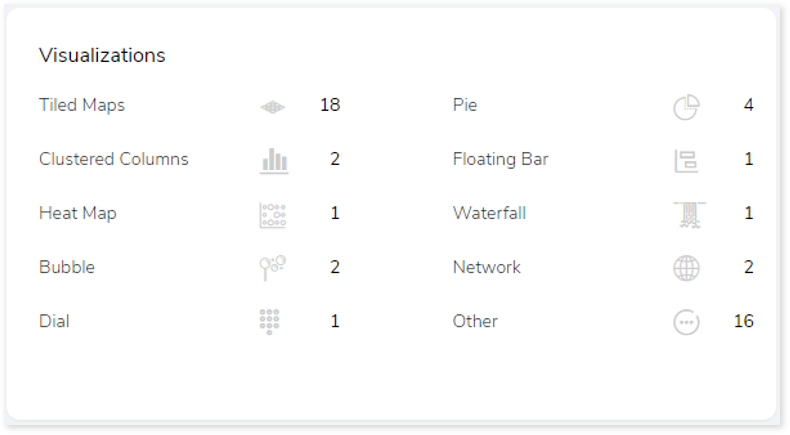
Visualizations
This section displays all the graphical visualization available in the source scripts such as graph, heat map, chart etc. This visual representation of data makes it easy to understand the data.
Entities
This section displays details of the entities including total, used, and unused tables along with their distribution across namespaces.
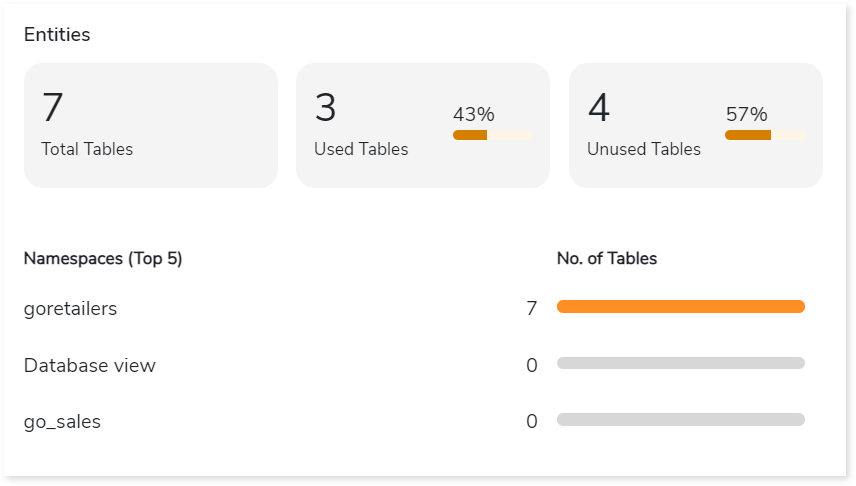
- Total Tables: Displays total number of tables.
- Used Tables: Displays total number of tables that are used in reports.
- Unused Tables: Displays the total number of tables that are not used in reports.
- Namespaces: Lists the top 5 namespaces along with the number of associated tables, arranged in descending order based on the table count.
Namespaces
Namespace is a set of entities used to manage and organize data. This section displays details of the namespaces including total, used, and unused namespaces along with their distribution across packages.
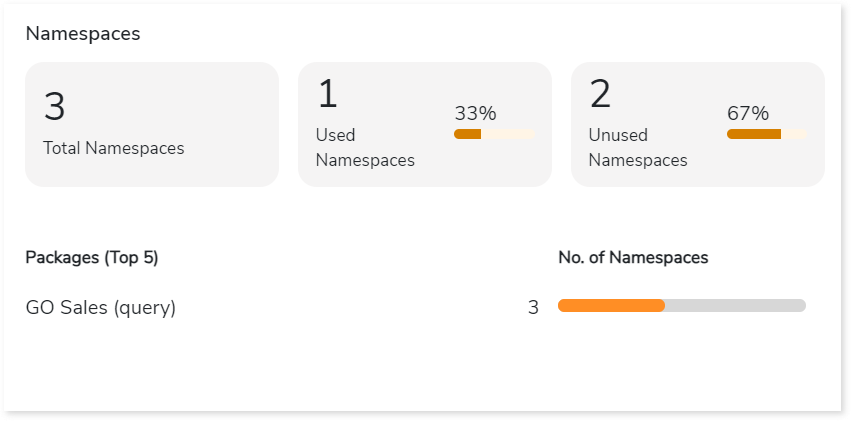
- Total Namespaces: Displays total number of namespaces.
- Used Namespaces: Displays total number of namespaces that are used in report.
- Unused Namespaces: Displays the total number of namespaces that are not used in reports.
- Packages: Lists the top 5 packages along with the number of associated namespaces, arranged in descending order based on the namespace count.
Filters
This section provides information about total, model, and report filters along with their types.

- Total Filters: Displays total number of filters.
- Model Filters: Displays number of model filters. Model filters are filters applied in the model dataset.
- Report Filters: Displays number of report filters. Report filters are filters applied within the reports.
- Filter Type: There are three types of filters:
- Detailed: Filters are applied to each row of the data.
- Summary: Filters are applied to refine the summary data.
- Slicer: Filters data based on specific categories or values.
Orchestration Jobs
Summary
This section summarizes the input AutoSys scripts, including the number of files, boxes, jobs, and so on.
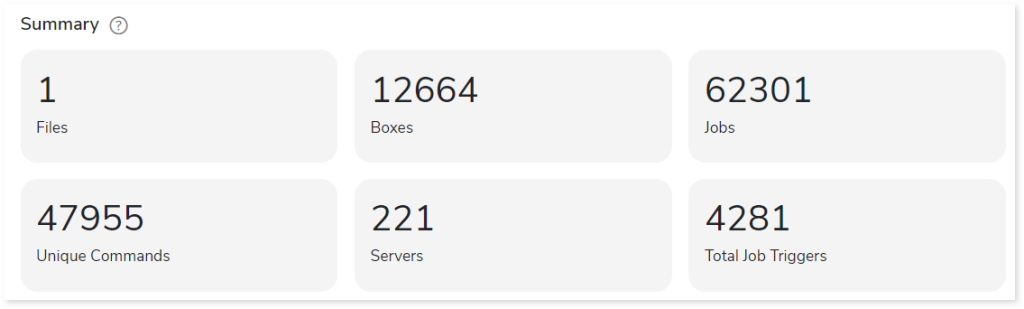
- Files: Number of input source files.
- Boxes: A box job is a container for multiple jobs. It controls scheduling, monitoring, and executing tasks.
- Jobs: Controls the system for scheduling, monitoring, and executing tasks.
- Unique Commands: Displays the number of unique commands.
- Servers: Displays the number of database servers where the AutoSys job details are stored.
- Total Job Triggers: Displays the total number of triggers.
Job Type
This section provides comprehensive information about Autosys job types along with its counts.
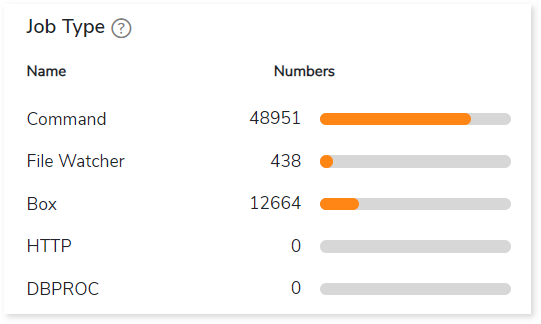
- Command: Used to execute workloads.
- File Watcher: Used to keep track of the presence and size of files.
- Box: A box job is a container for multiple jobs.
- HTTP: Used to invoke HTTP services.
- DBPROC: Used to execute database stored procedures.
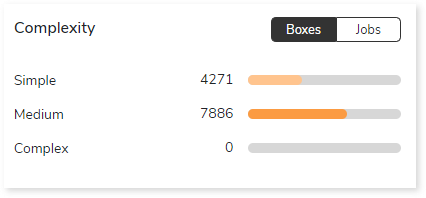
Complexity
This section provides a summarized graphical representation of the complexity of jobs and boxes that helps in making different decisions, including budget estimation and assessing the effort required to transform the workloads.
Job Trigger Frequency
This section provides information about triggers, including the total number of triggers, frequency (such as daily, weekly, and others), and the count of scheduled triggers.
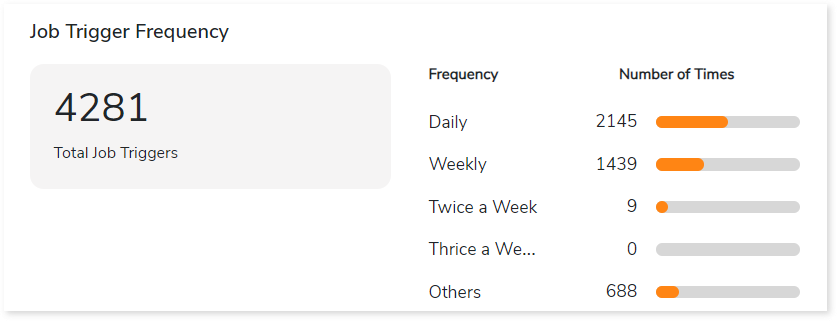
- Total Job Triggers: Displays the total number of triggers.
- Frequency: Displays the frequency of jobs such as daily, weekly, twice a week, etc., along with the number of triggers.
Watch Files
This section provides comprehensive information about watch files, including the total number of watch files, types, and its count.
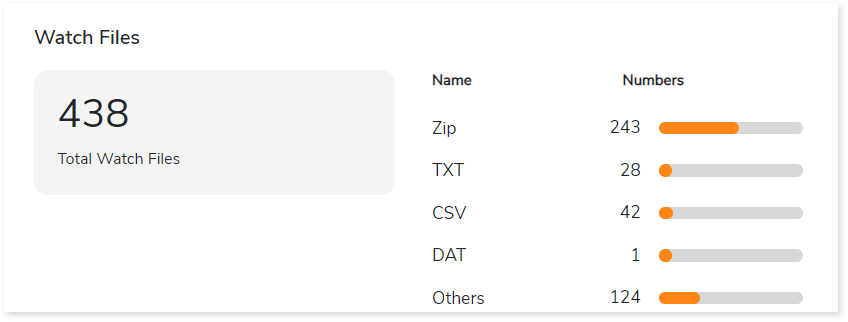
- Total Watch Files: Displays the total number of watch files.
- Name: Displays top 5 watch file types such as Zip, TXT, CSV, etc., along with its count.