Configuring On-premises to Cloud Transformation
In the Transformation stage, the legacy codes and the business logic are transformed to the preferred target.
To configure the Transformation stage, follow the below steps:
- In Source Type, select the required source data store, such as Netezza, Oracle, SQL Server, Teradata, Vertica, and more.

- In Input Type, select the type of input script, such as SQL/BTQ/Procedure or KSH.
- In Target Type, select the preferred target type, such as Spark, Snowflake, Amazon Redshift, and so on.
- In Output Type, select the output type (such as Python, RSQL) to generate artifacts in that format.
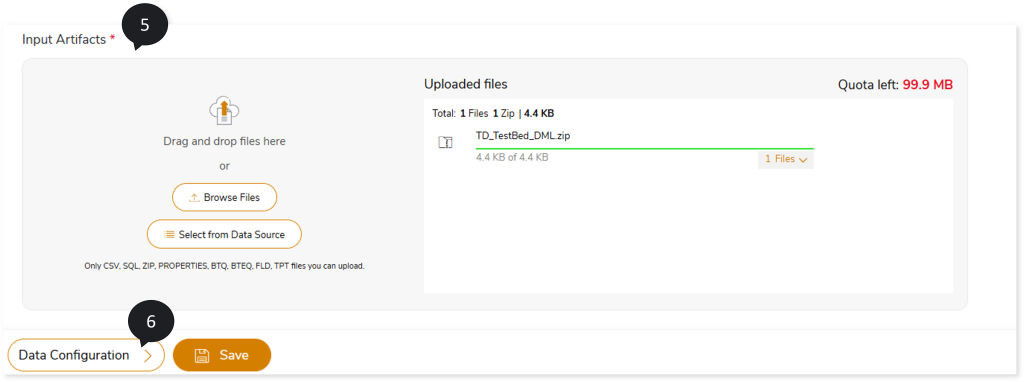
- In Input Artifacts, upload the files that you need to transform to the target source.
- Click Data Configuration to configure the data.
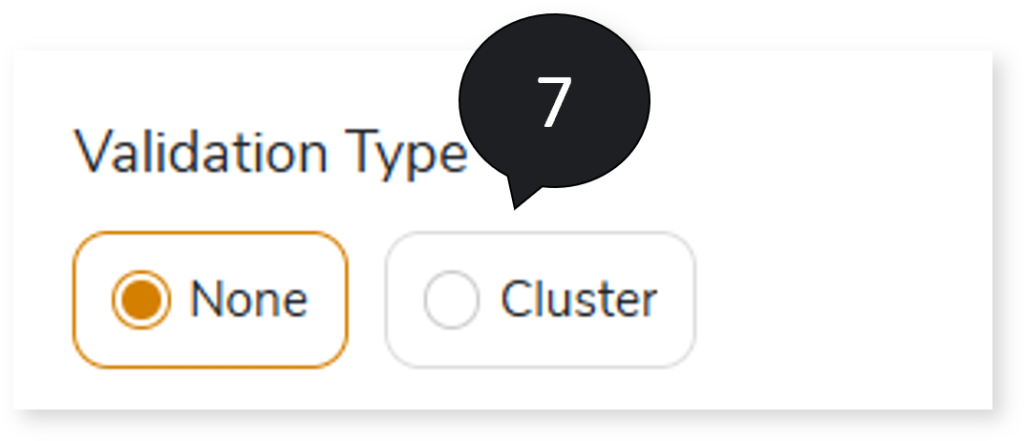
- In Validation Type, select the validation type:
- None: Performs no validation.
- Cluster: Syntax validation is performed on queries transformed by the LeapLogic Core transformation engine.
- In AI Augmentation, select the preferred Transformation and Review models to convert queries that require augmented transformation and perform syntax validation for accuracy and optimal performance. To convert queries using AI Augmentation, you must provide the source and target combinations in the Add New Sources and Targets page (Governance > Intelligence Modernization > Custom Source/ Target > Add New Sources and Targets)
To view the detailed steps for adding source and target combinations in the Add New Sources and Targets page, click here.
- Transformation Model: Select the preferred Transformation model to convert queries that are not handled by the default LeapLogic Core transformation engine to the target equivalent. The Transformation Model supports both Open-Source AI models (LeapLogic) and Enterprise AI models (Databricks AI and Amazon Bedrock such as Claude, Nova, etc.) for query transformation. It also identifies query types even if conversion fails.
The Open-Source AI models include:
- OpenOrca 7B, GPTQ 4-bit quantized Model (Hugging Face), Llama 8B, 16-bit quantized Model (Ollama), and Llama 8B, 4-bit quantized Model (Ollama): To convert small- to medium-sized SQLs.
- Code Llama 34B, GPTQ 4-bit quantized Model (Hugging Face): To convert large-sized SQLs and procedural code.
- In Additional Prompt, provide supplementary instructions in addition to system-generated prompts. For example: Ensure the given DDL metadata is applied during conversion and validation for casting, precision, and scale based on the target system.
- In Response Fine Tuning, provide examples based on the additional prompt to fine-tune the response to align the generated output with your preferred level of detail. For example, input could be INSERT INTO CUSTOMER (cust_id, cust_name, credit_limit, discount_rate) VALUES (1, ‘JohnDoe’, 12345.6789, 0.123456); and the expected output could be INSERT INTO CUSTOMER (cust_id, cust_name, credit_limit, discount_rate) VALUES (1, ‘JohnDoe’, CAST (12345.6789,numeric(10,2)), 0.123456);
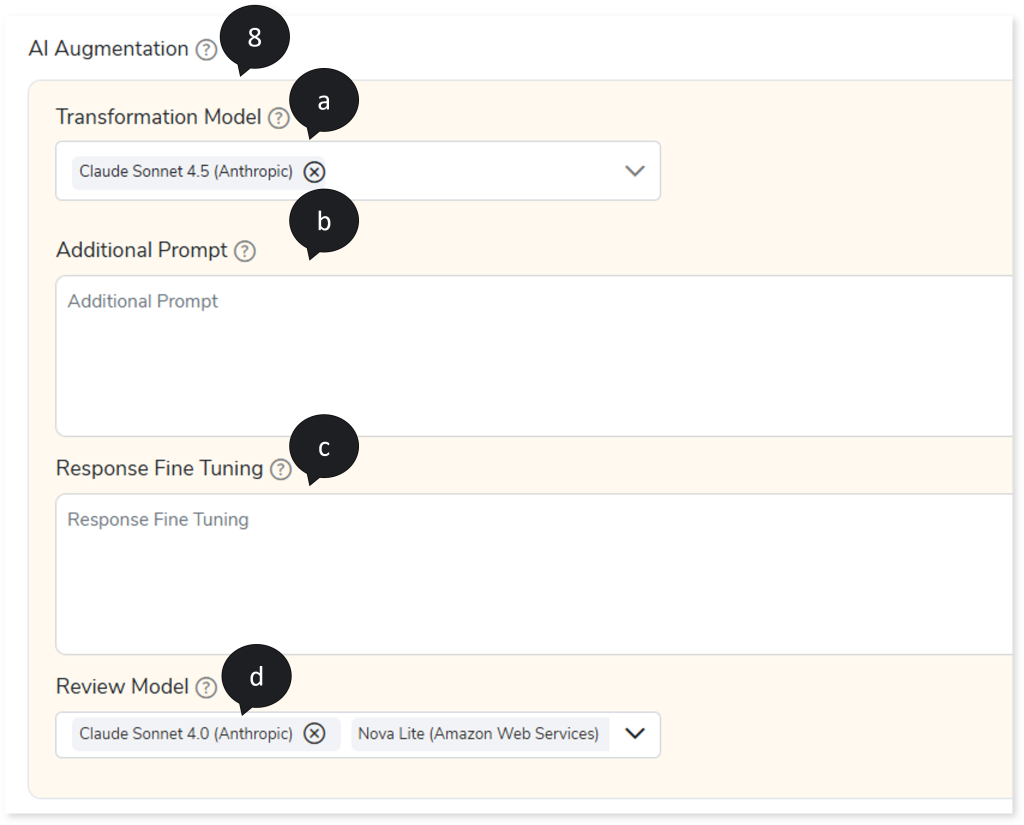
- Review Model: Select one or more Review models from to perform syntax validation on the queries transformed by the LeapLogic Core engine and the Transformation Model. The Review Model validates the transformed queries syntactically, excluding any procedural logic, and suggests corrections where required. You can configure multiple Review models. When multiple Review models are configured:
- The first Review model validates the queries transformed by the LeapLogic Core engine and the Transformer model. It validates the transformed queries syntactically, excluding any procedural logic. If any queries are identified as incorrectly transformed, it suggests updated queries.
- The updated queries are then passed to the next Review model, which validates them and suggests corrections, if required.
- This process continues through all configured Review models until the queries are successfully validated, and the optimized queries are generated.
This validation process ensures higher accuracy, better performance, and more efficient transformation.
To access this intelligent modernization feature (AI Augmentation), ensure that your account has the manager and llexpress_executor roles.
To view the detailed steps for assigning manager and llexpress_executor roles to your account, click here.
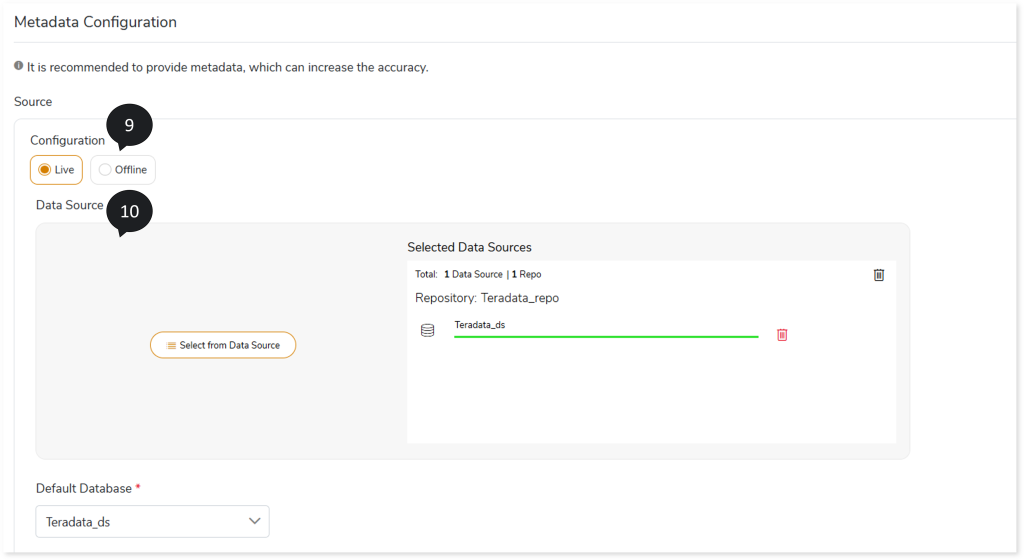
- In Source Configuration, select the source configuration as Live or Offline.
- If the selected Source Configuration is:
- Live: Upload the data source and select the Default Database.
- Offline: Upload the DDL files. It supports .sql and .zip file formats.
- In Target Configuration, select the target configuration as Live.
- Upload the target data source.
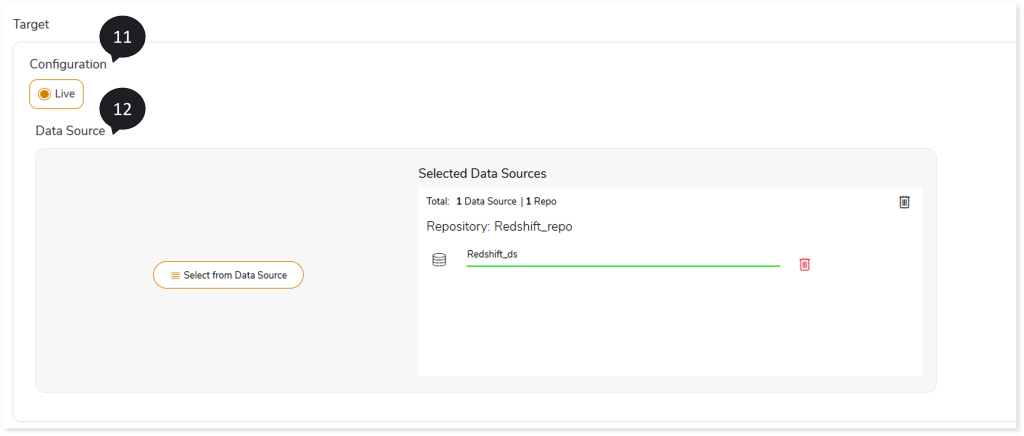
- In File Format, select the storage type as ORC, Parquet, Text File, or Avro
- In Mapping as per Changed Data Model, upload files for mapping between source and target tables.
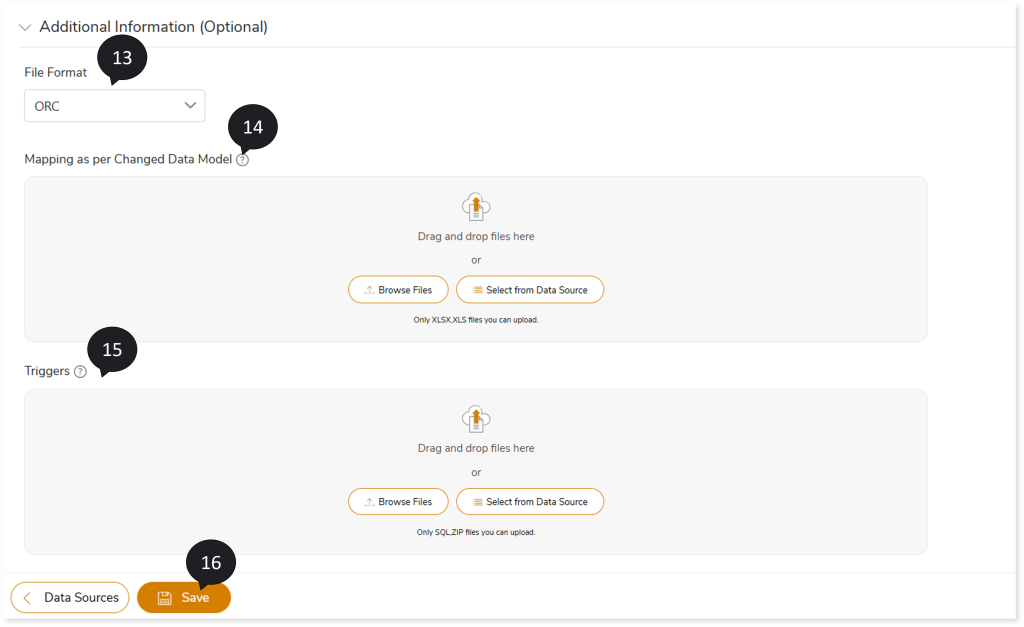
- In Triggers, upload the trigger statements for a more accurate conversion.
- Click Save to save the Transformation stage.
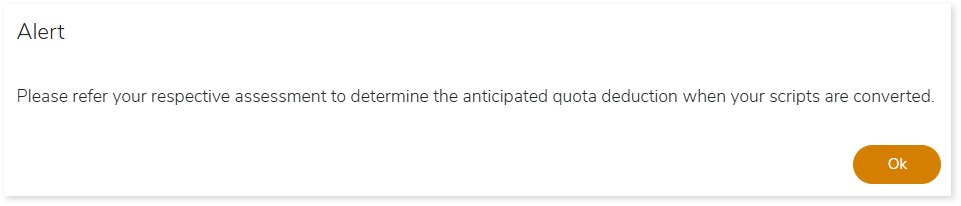
- An alert pop-up message appears. This message prompts you to refer your respective assessment to determine the anticipated quota deduction required when converting your scripts to target. Then click Ok.
- Click the Execute icon to execute the integrated or standalone pipeline. Clicking the Execute icon navigates you to the pipeline listing page which shows your pipeline status as Running state. It changes its state to Success when it is completed successfully.
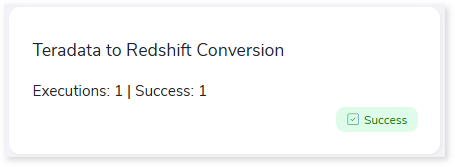
- Click on your pipeline card to see reports.
To view the On-premises to Cloud Transformation, visit On-premises to Cloud Transformation Report.