Configuring Multi Algo Stage
The Multi Algo stage configures the appropriate values for different environmental variables in the Ab Initio ETL graph. It executes the artifact that is generated from the Ab Initio conversion.
In This Topic:
Overview
In this section, you can customize the name for the Multi Algo stage and can give a suitable description that describes the purpose and scope of the stage. By default, Multi Algo is provided in the Name field.
Transform
The input to this transformation can be queries, commands, or even a property file provided from the backend. This transformation produces an optimal configuration of the required environment variables as well as tuning of the Ab Initio ETL graphs.
Multi Algo supports four types of algorithms:
- HQLExecutor: Used to execute Hive queries.
- SSHExecutor: Used to execute SSH commands. For example, if you need to execute commands like deleting or creating a file.
- NifiExecutor: Used to load the data file from a system into the HDFS.
- SparkExecutor: Used to execute Spark submit command.
To configure the Multi Algo stage, follow the below steps:
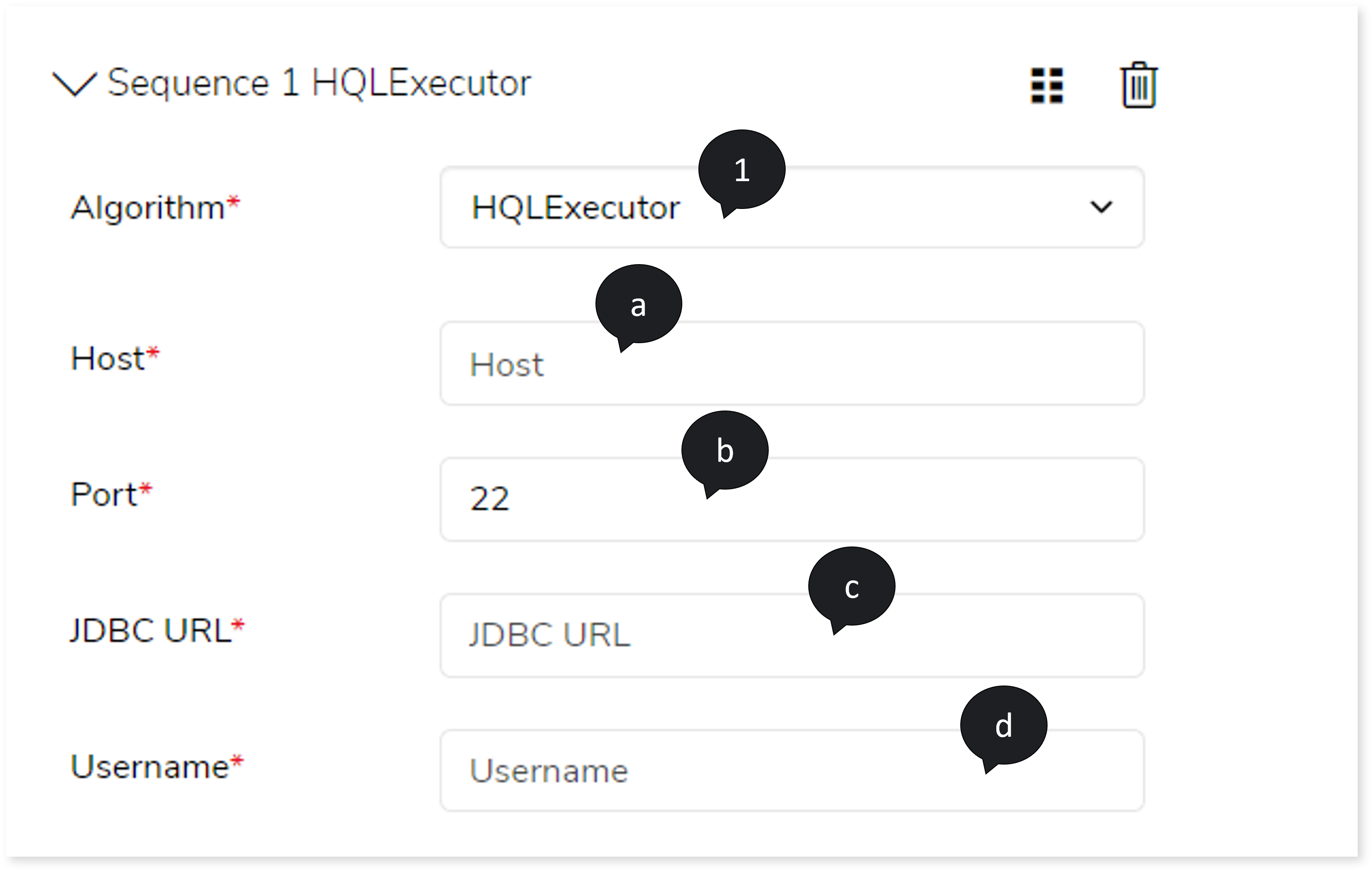
- Choose the Algorithm such as HQLExecutor, SSHExecutor, NifiExecutor, or SparkExecutor.
If you choose Algorithm as HQLExecutor, then:
- In Host, provide the host address to connect Hive.
- In Port, provide the port number.
- In JDBC URL, provide the JDBC URL.
- In Username, enter the username.
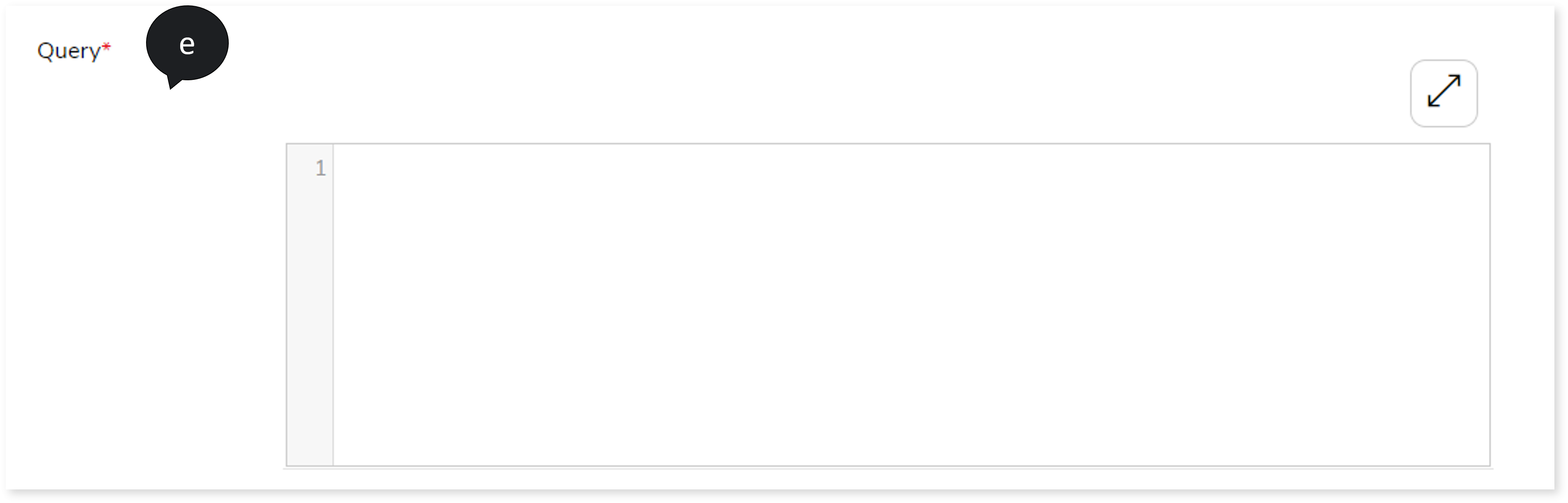
- In Query, enter the query.
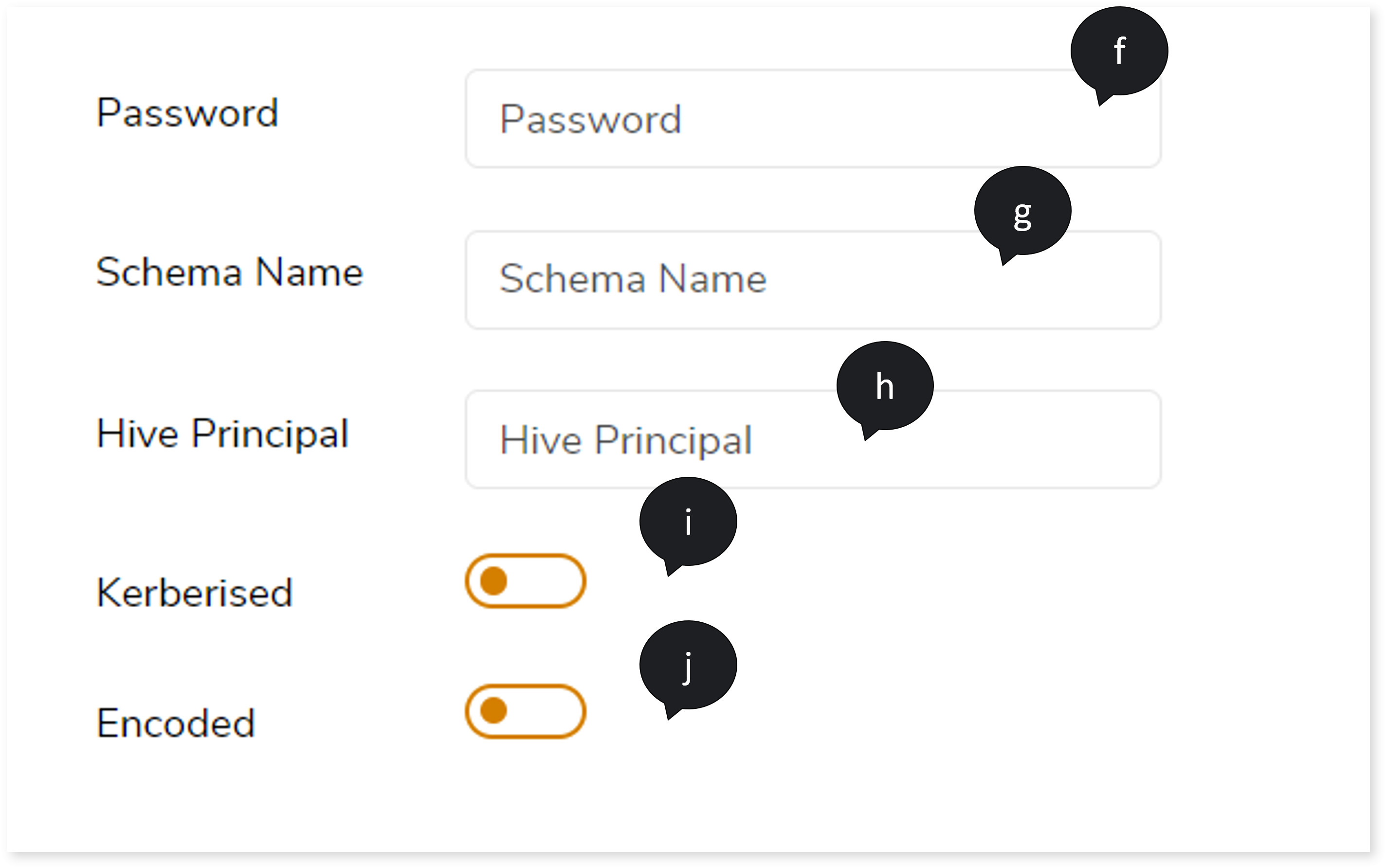
- In Password, enter the appropriate Password.
- In Schema Name, provide the schema name.
- In Hive Principal, provide the hive principal url.
- If the network authentication protocol is Kerberos, turn on the Kerberised toggle.
- If the query is encoded, turn on the Encoded toggle.
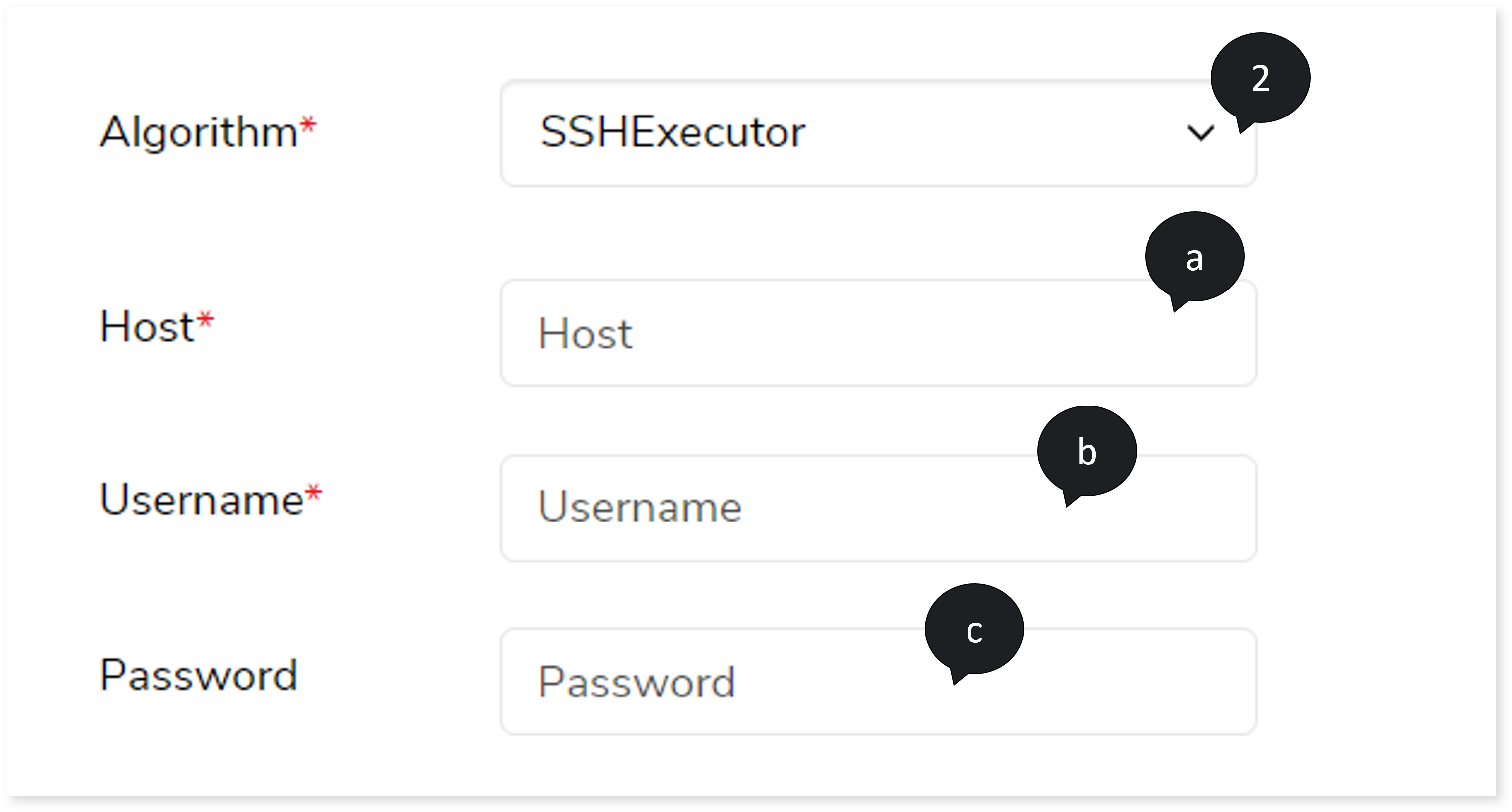
- If you choose the Algorithm as SSHExecutor, then:
- In Host, provide the host address.
- In Username, enter a valid username.
- In Password, enter the appropriate password.
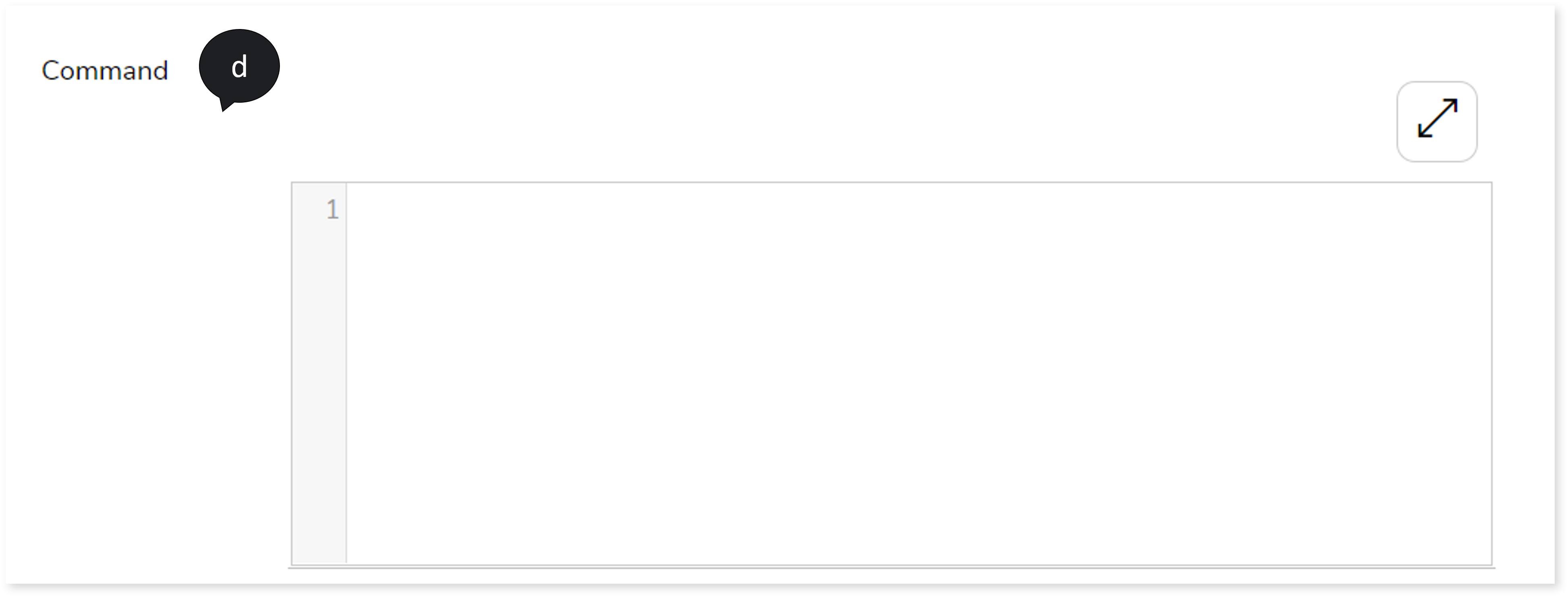
- In Command, enter the command or query.
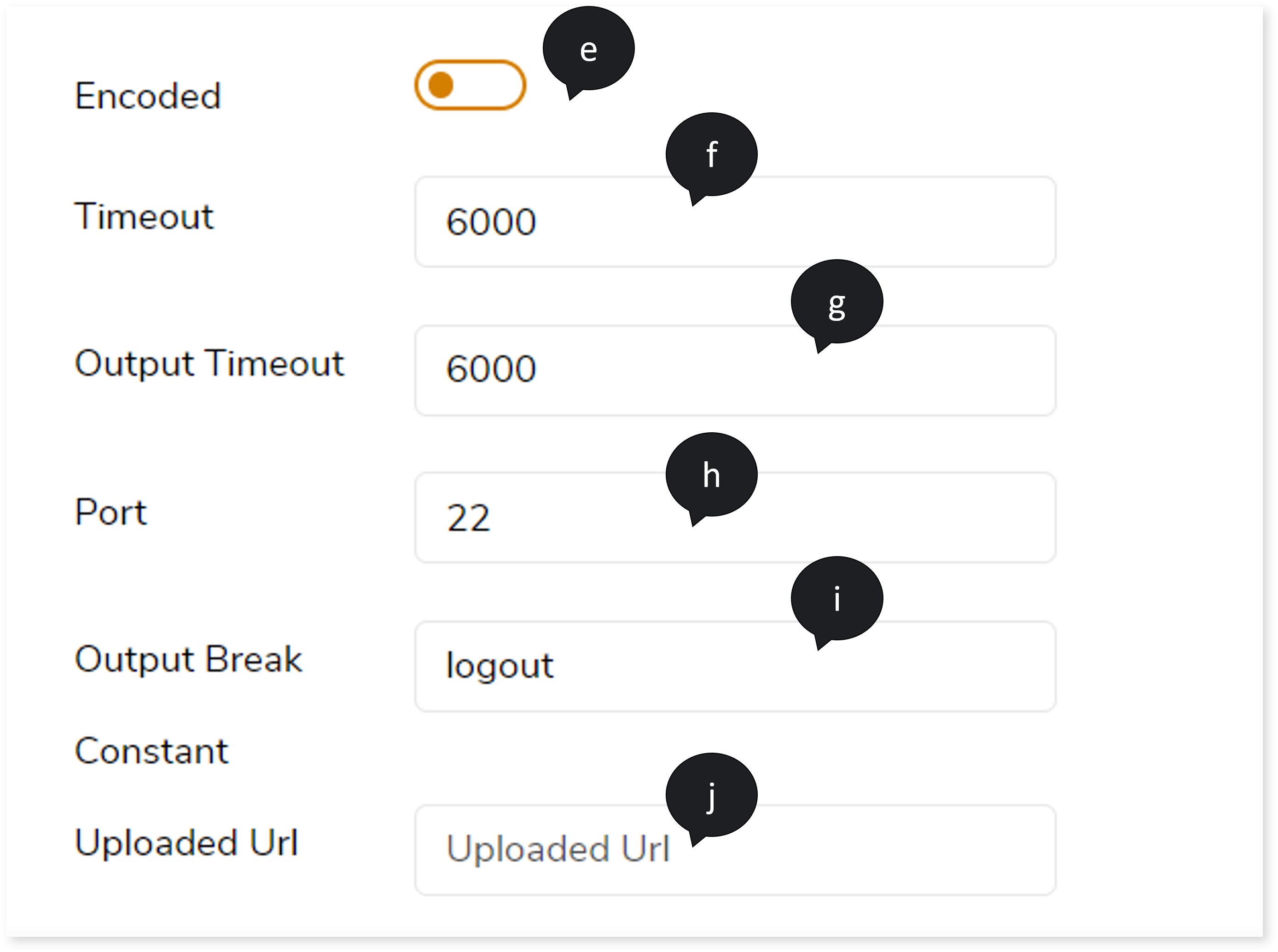
- If the query is encoded, turn on Encoded toggle.
- In Timeout, provide the time in milliseconds. Time out is the waiting time for a command to be executed. The system terminates the execution if the command is not executed within the specified time.
- In Output Timeout, provide the time in milliseconds. As soon as the command executes, the system reads the output. If the system cannot read the output within the specified time, it terminates the process.
- In Port, provide the port number.
- In Output Break Constant, enter the keyword to break the command during execution. For example, if you enter the keyword as logout, whenever the system encounters the keyword logout in the output, it breaks the command.
- In Uploaded Url, specify the URL of the files that you need to upload and execute. If you specify the URL, the system downloads the file and executes the command.
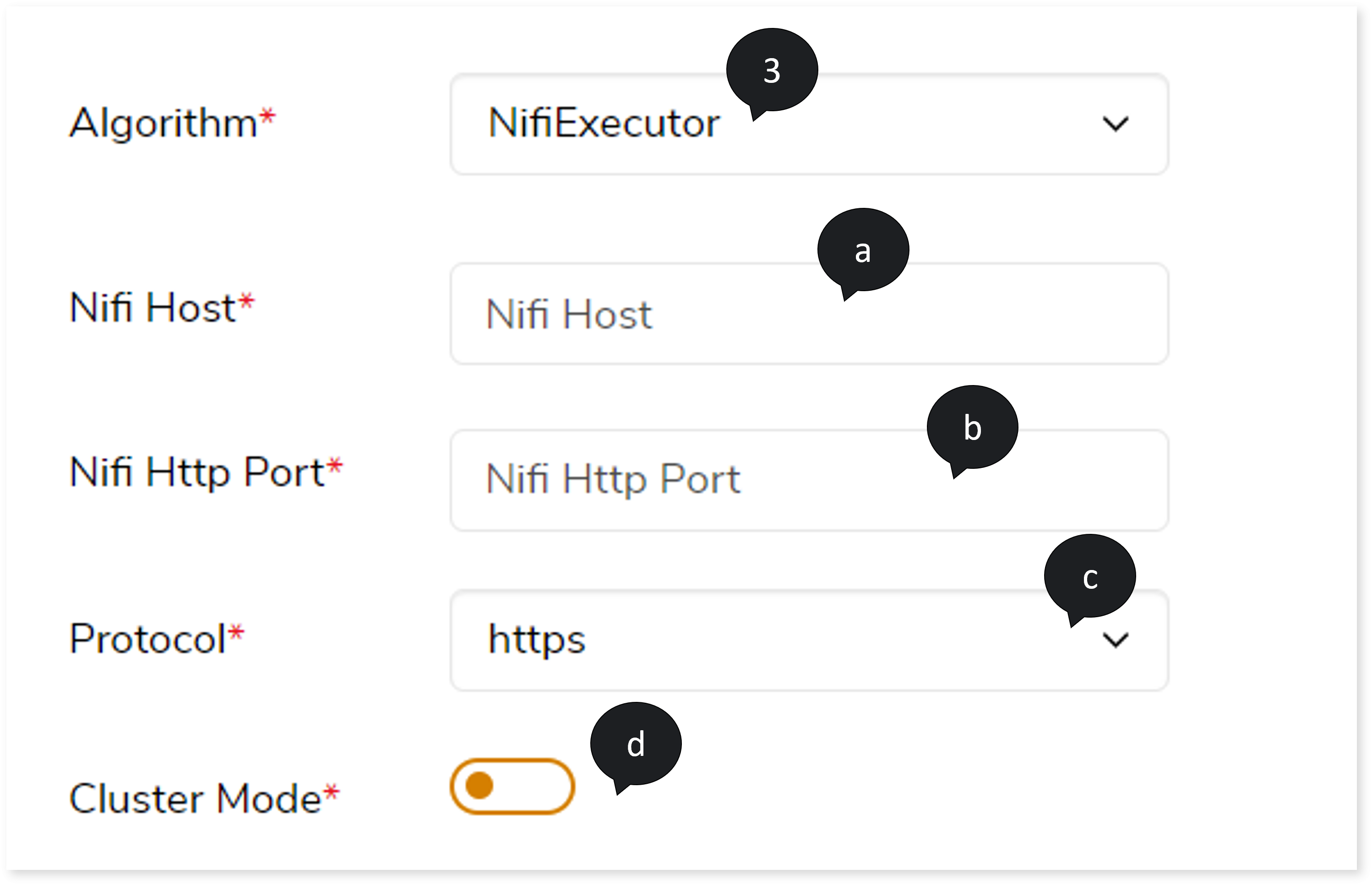
- If you choose Algorithm as NifiExecutor, then:
- In Nifi Host, provide the host address.
- In Nifi Http Port, provide the port number.
- In Protocol, select the protocol such as http or https.
- Turn on the Cluster Mode toggle.
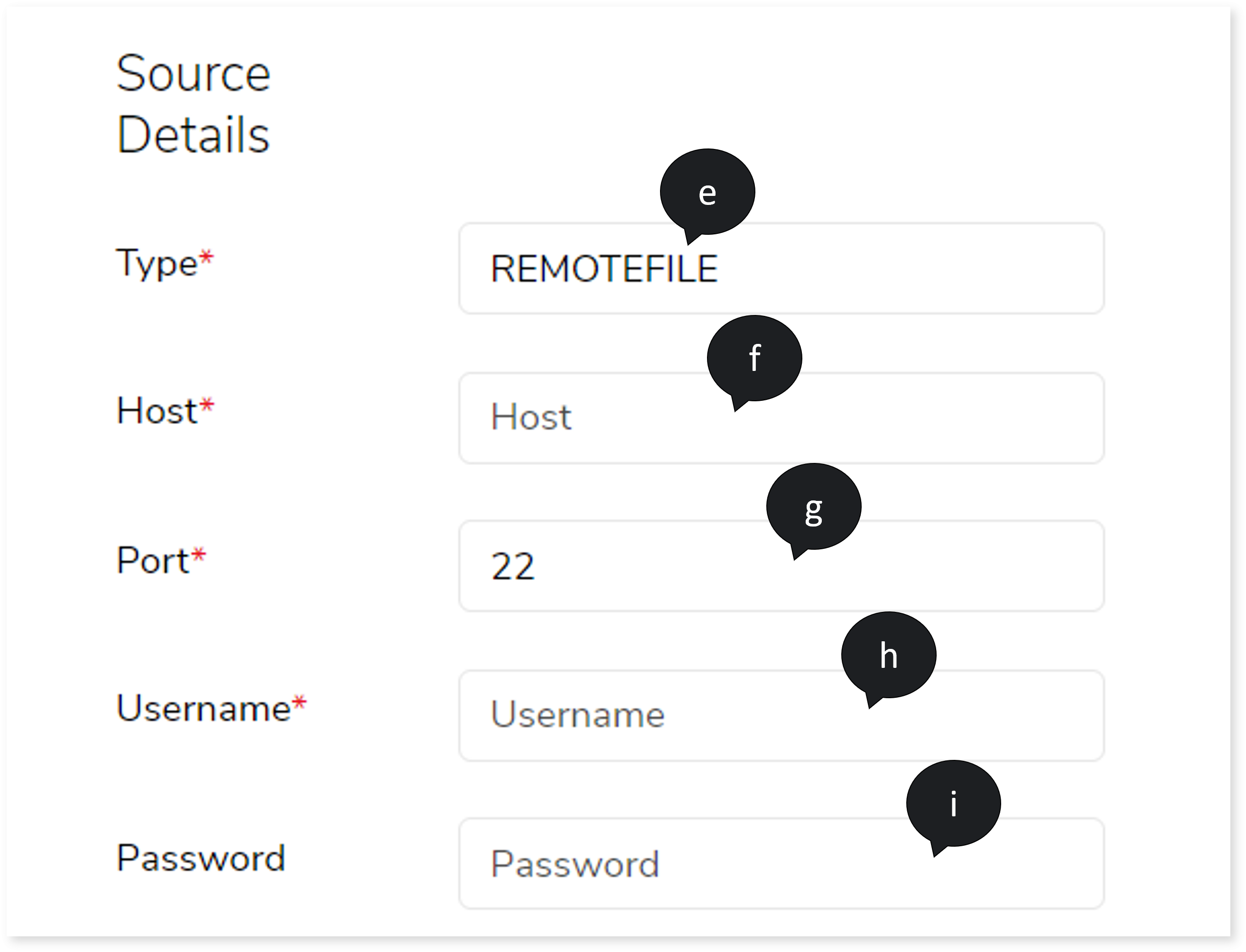
- In Type, select the source type such as REMOTEFILE.
- In Host, provide the host address.
- In Port, provide the port number.
- In Username, enter a valid username.
- In Password, enter the appropriate password.
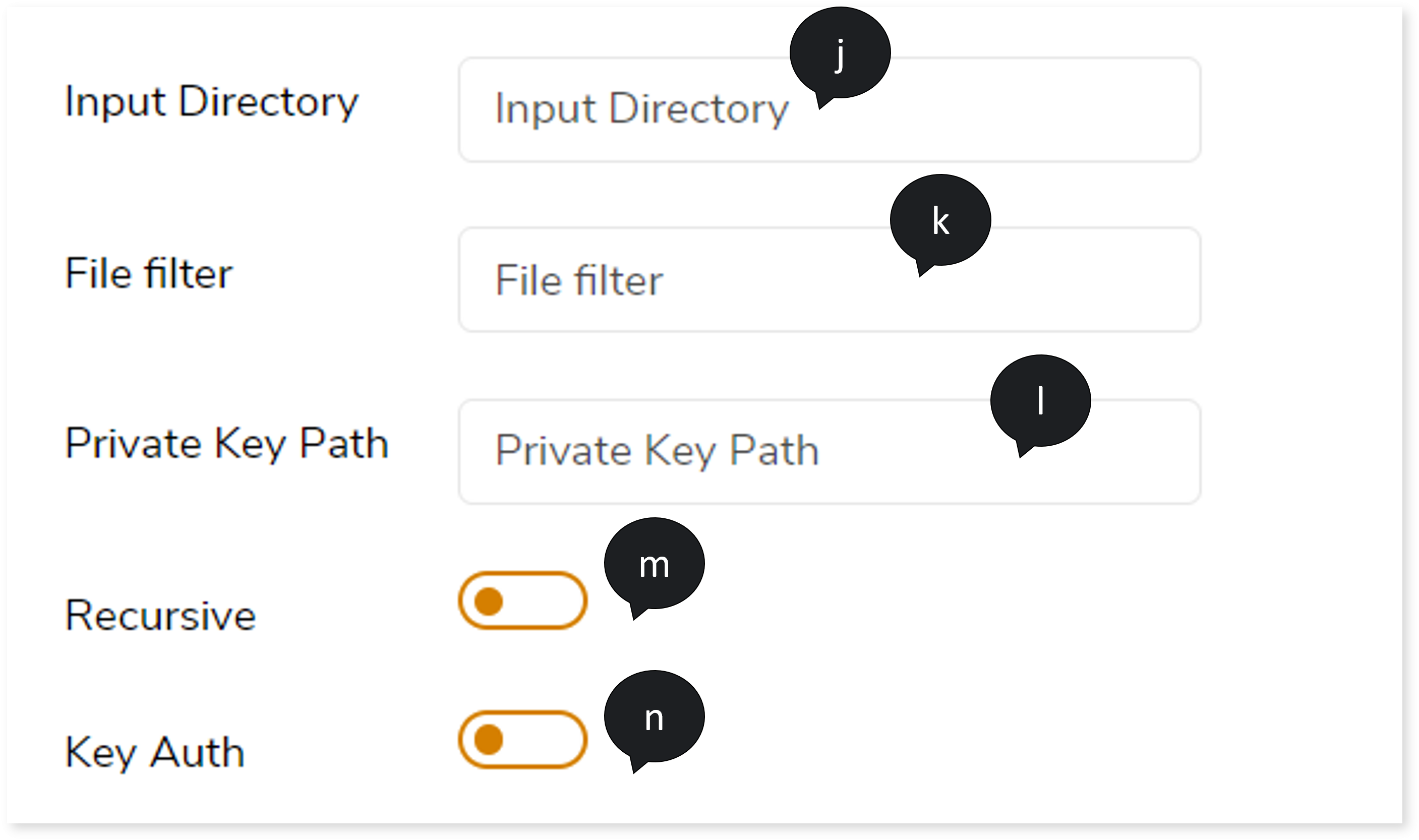
- In Input Directory, provide input directory details.
- In File Filter, provide the file filter details.
- In Private Key Path, provide the private key path details.
- Turn on Recursive toggle.
- To enable the authentication, turn on Key Auth toggle.
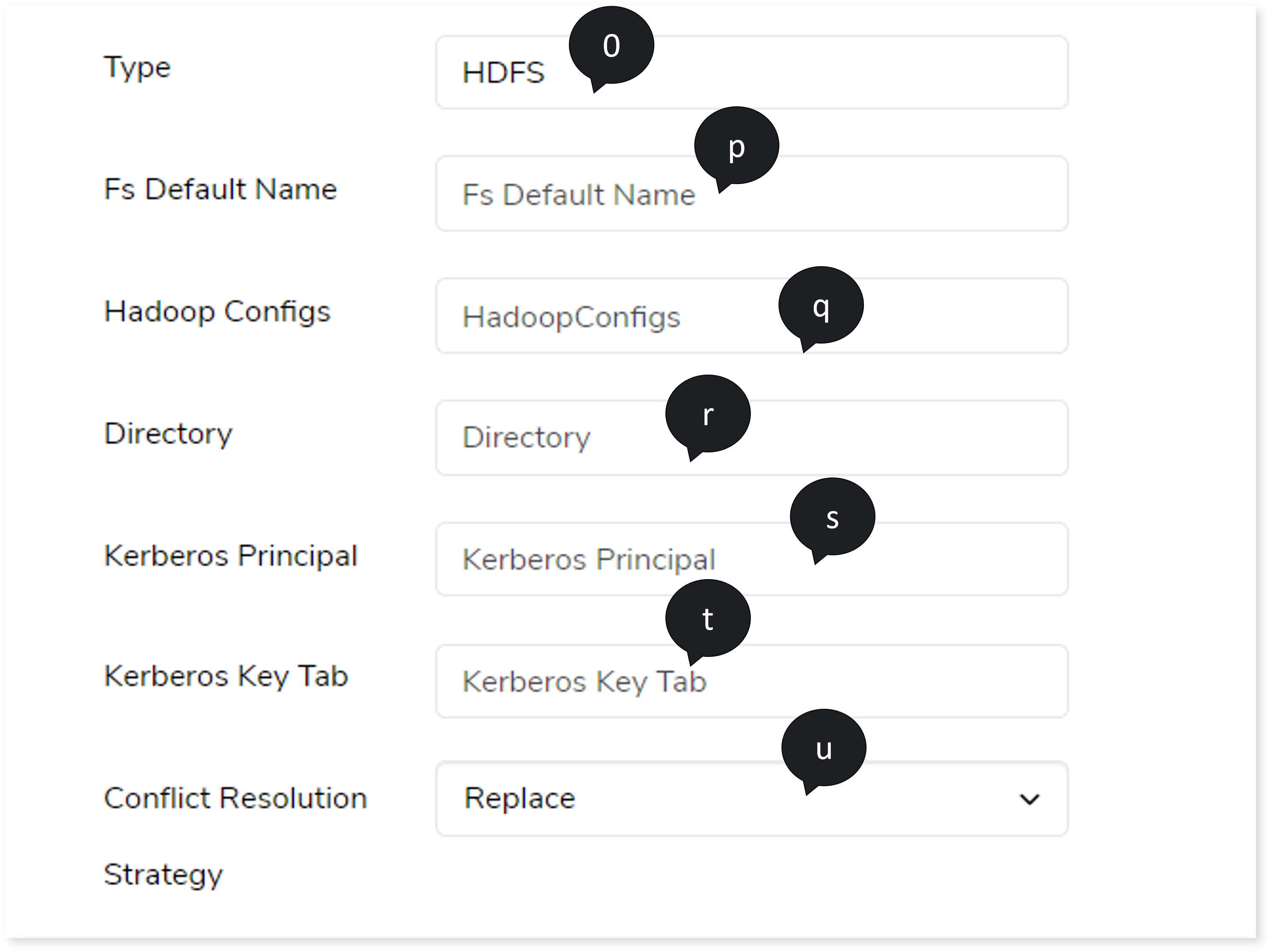
- In Type, provide the target type to load the data.
- In FS Default Name, provide the file system name. This is the default directory. If a directory name is not specified, the data will be loaded into this default directory.
- In Hadoop Configs, provide the Hadoop configuration details.
- In Directory, provide the directory details.
- In Kerberos Principal, provide the Kerberos principal details.
- In Kerberos Key Tab, provide the Kerberos key tab information.
- In Conflict Resolution Strategy, provide the strategy such as Replace, Fail, Ignore, or Append.
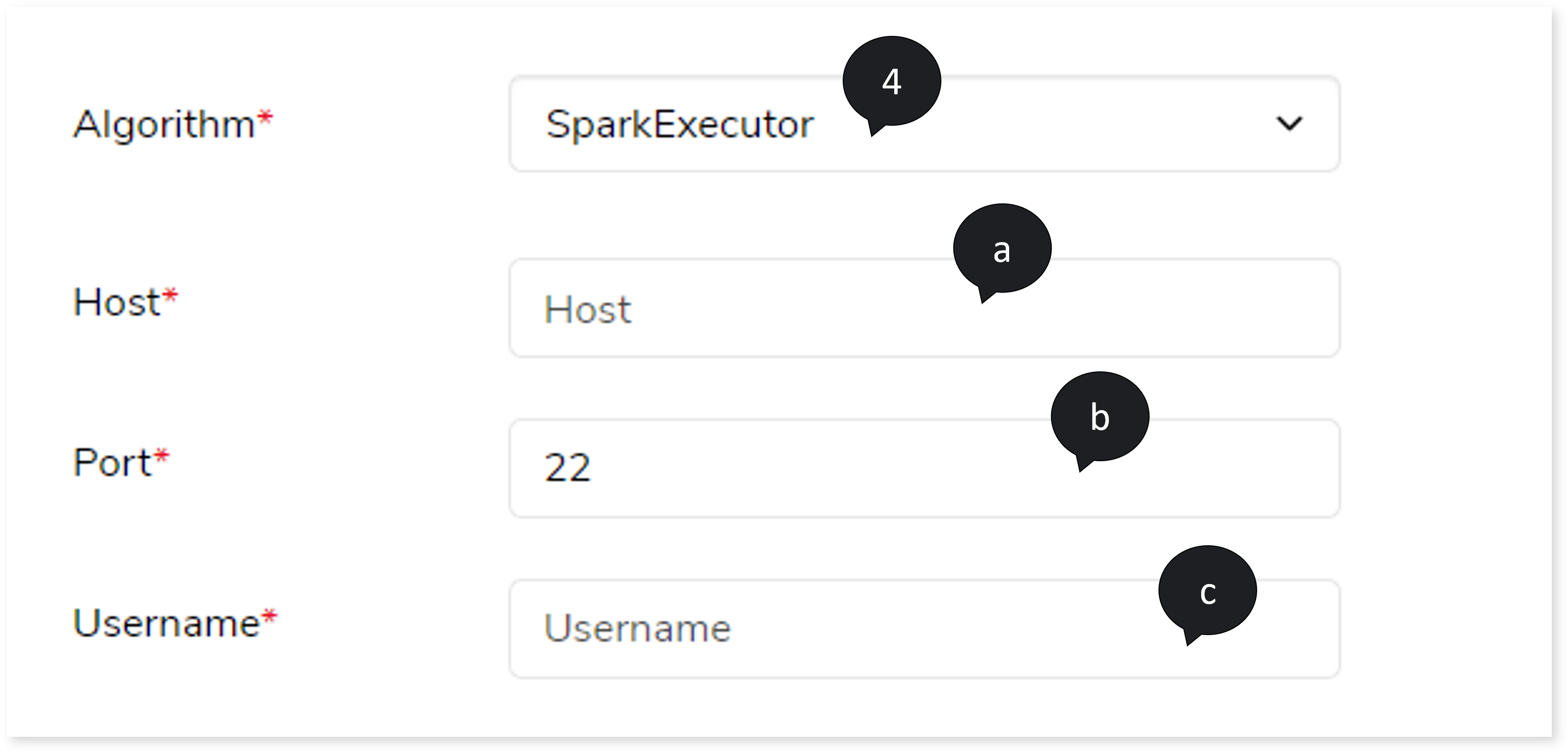
- If you choose Algorithm as SparkExecutor, then:
- In Host, provide the host address.
- In Port , provide the port number.
- In Username, provide a valid username.
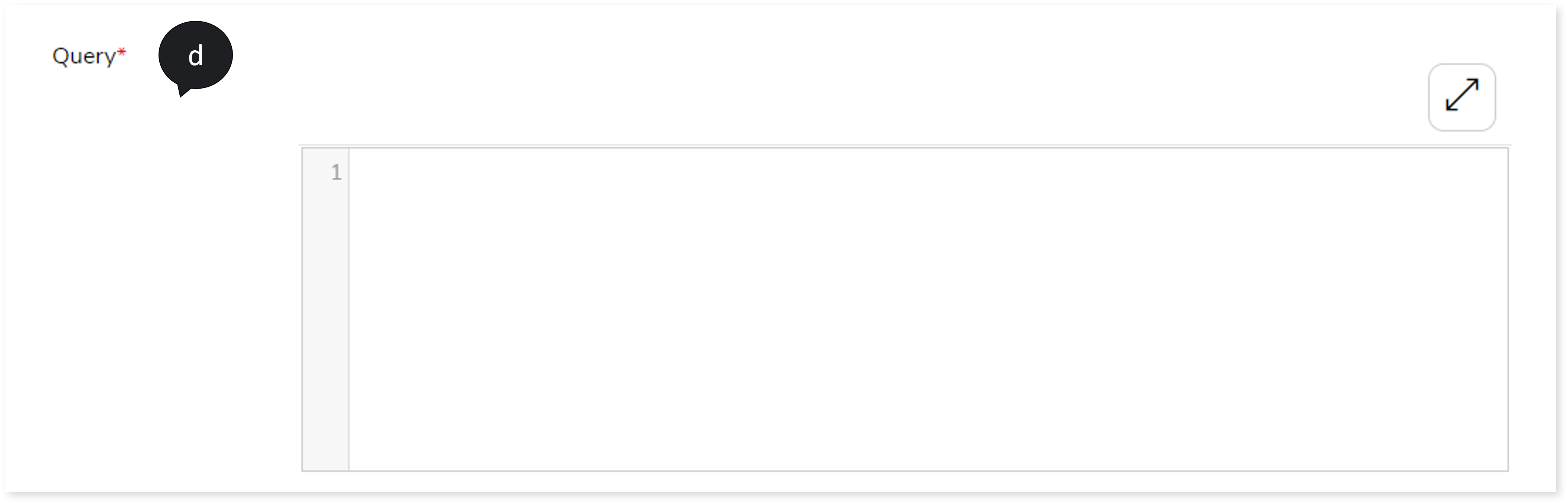
- In Query, enter the query.
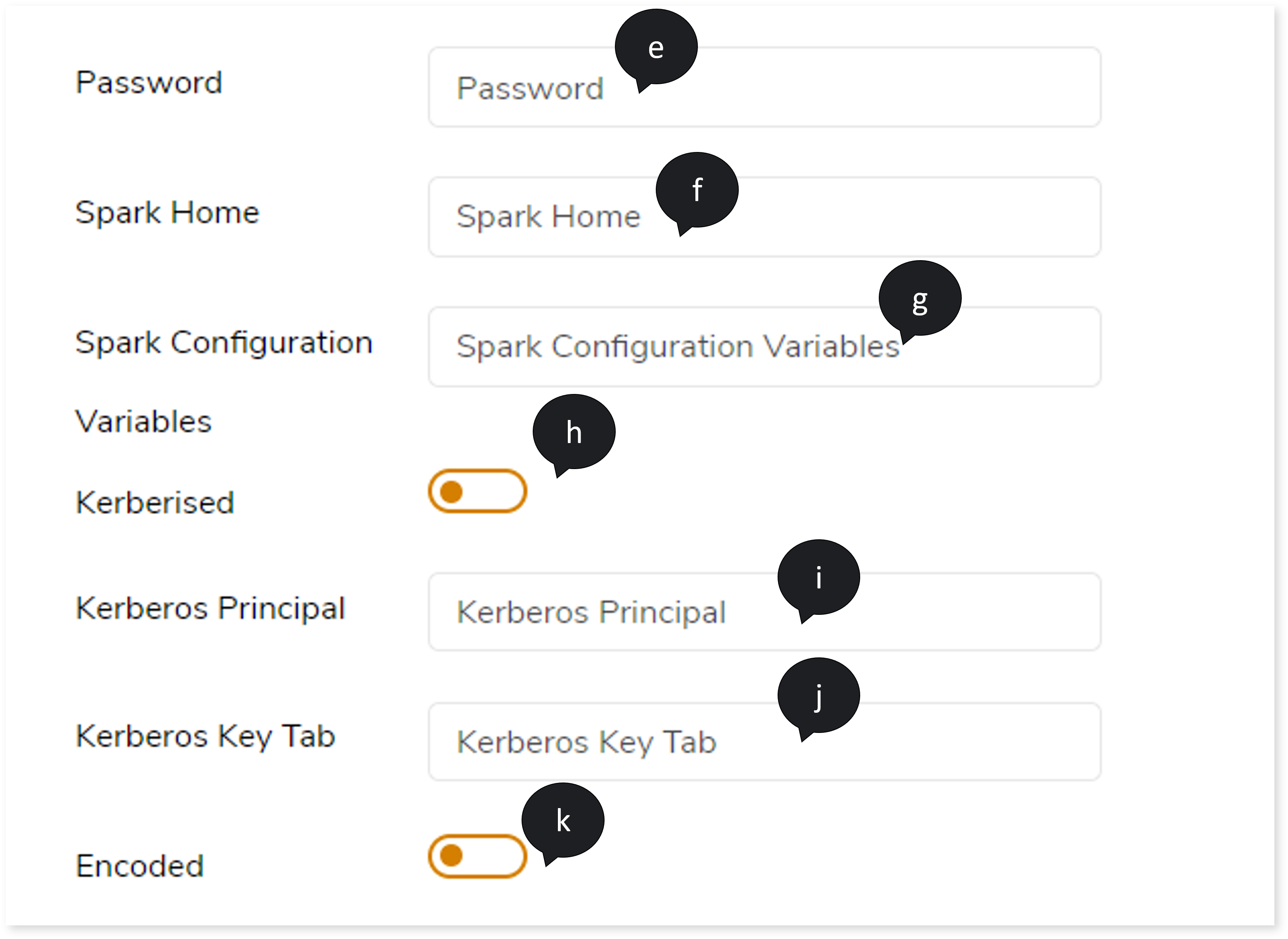
- In Password, enter the appropriate password.
- In Spark Home, provide the spark home path if the spark submit command is not directly available in the path variable.
- In Spark Configuration Variables, specify spark configuration variables to provide other spark configuration related parameters. Here you can provide any additional parameters which can be used to execute your spark job.
- If the network authentication protocol is Kerberos, turn on the Kerberised toggle.
- In Kerberos Principal, provide the Kerberos principal details if your cluster is Kerberos.
- In Kerberos Key Tab, provide the Kerberos key tab information.
- If the query is encoded, turn on the Encoded toggle.
- Click
 to add new algorithms.
to add new algorithms.
- Click Save to save the Multi Algo stage. When a Multi Algo stage is successfully saved, the system displays an alerting snackbar pop-up to notify the success message.

- Click
 to execute the pipeline.
to execute the pipeline.
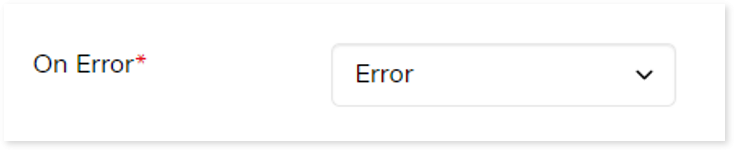
Output
In this section, you can configure the output of this stage for navigation to a further stage in case of any error. By default, the Output configuration is set to Error whenever the system encounters an error, or that can be configured to Continue, Stop, or Pause as required.