Ab Initio Assessment Report
This topic contains information about the Ab Initio assessment report. The assessment assesses workloads and produces in-depth insights that help to plan the migration. The Ab Initio assessment accepts various file formats such as XFR, DML, KSH, PLAN, and PSET. Among these, PLAN file provides detailed workflow for executing tasks and PSET file contains tasks or calls to other scripts such as BTEQ, etc.
In This Topic:
Highlights
The highlights section gives you a high-level overview of your assessment summary of the analytics performed on the selected workloads. It includes a graphical depiction of the complexity of files as well as the summary of the files used.
Summary
This section showcases an overview of input Ab Initio graphs and the associated workload inventory. It provides insights into the total number of files, components, Plan files, tasks and more.
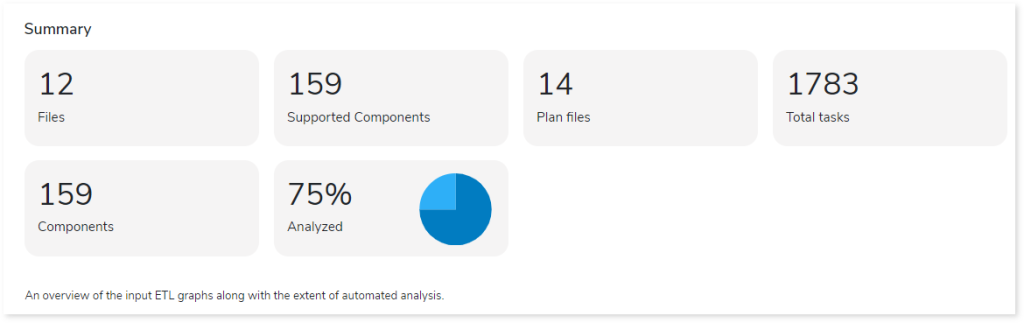
- Files: Displays the total number of Ab Initio source files.
- Supported Components: Displays the number of unique components identified within the source files.
- Plan files: Displays the total number of Plan files. PLAN file provides detailed workflow for executing tasks.
- Total tasks: Displays the number of tasks within the Plan files.
- Components: Displays the total number of components.
- Analyzed: Displays the percentage of analyzed Ab Initio workloads.
Complexity
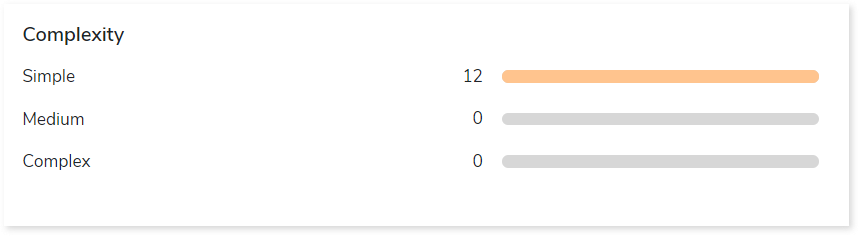
This section provides a summarized graphical representation of the complexity of the Ab Initio ETL graphs that helps in making different decisions, including budget estimation and the effort required for migration.
Analysis
This topic provides a detailed examination of source and Plan files.
Source Analysis
This section provides a comprehensive report of the source file including statistical information about file complexity, input/output sources, components, and more.

- Files: Displays the name of the file.
- Input Sources: Provides the number of input files identified in the attached artifacts.
- Output Sources: Provides the number of target files for jobs.
- Components: Displays the total number of components. Components are the building blocks to perform a task. These components are mainly categorized into the Dataset components and the Program components, where the dataset components store the data, and the program components process the data.
- Auto Conversion (%): Displays the percentage of auto-converted files.
- Raw Loc: Displays the number of lines of queries in the attached input.
- Complexity: Displays the complexity of files.
Plan File Information
This section provides detailed information about plan files, including associated PSET files, MP files, plan tasks, graph tasks, and more.

- File Name: Displays the name of the Plan file.
- Conditional Task: Displays the number of conditional tasks in each Plan file. Conditional task refers to the execution of tasks based on specific conditions.
- Graph Task: Displays the number of graph tasks in each Plan file. Graph task refers to the execution of graphs.
- Plan Task: Displays the number of plan tasks in each Plan file. Plan task refers to the execution of another Plan task.
- Program Task: Displays the number of program tasks in each Plan file. Program task refers to the execution of programs or scripts.
- MP Files: Displays the number of MP files that are associated with the Plan file.
- PSET Files: Displays the number of PSET files that are associated with the Plan file.
Lineage
End-to-end data and process lineage identify the complete dependency structure through interactive and drill-down options to the last level.
Typically, even within one line of business, multiple data sources, entry points, ETL tools, and orchestration mechanisms exist. Decoding this complex data web and translating it into a simple visual flow can be extremely challenging during large-scale modernization programs. The visual lineage graph adds tremendous value and helps define the roadmap to the modern data architecture. It deep dives into all the existing flows, like Autosys jobs, applications, ETL scripts, BTEQ/Shell (KSH) scripts, procedures, input and output tables, and provides integrated insights. These insights help data teams make strategic decisions with greater accuracy and completeness. Enterprises can proactively leverage integrated analysis to mitigate the risks associated with migration and avoid business disruption.
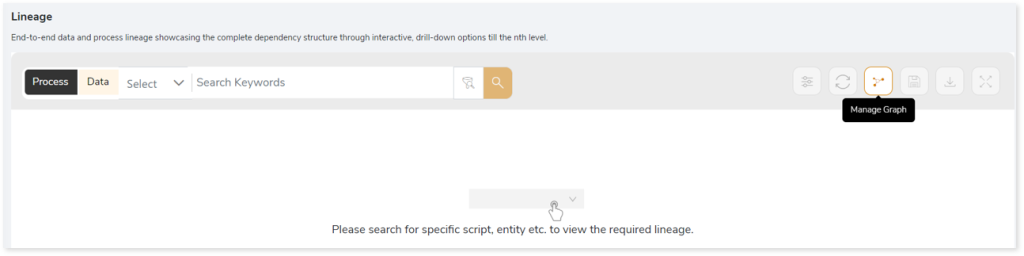
Now, let’s see how you can efficiently manage lineage.
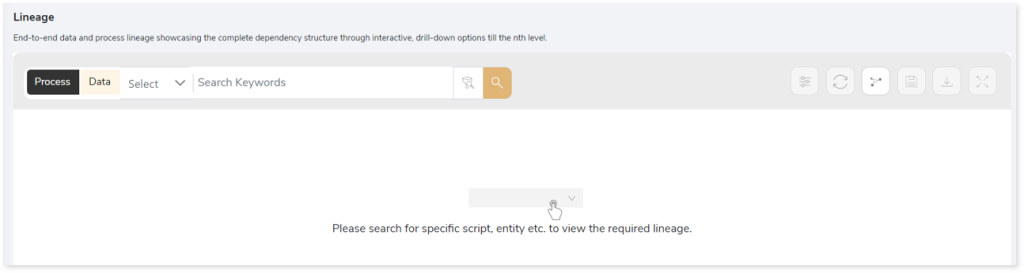
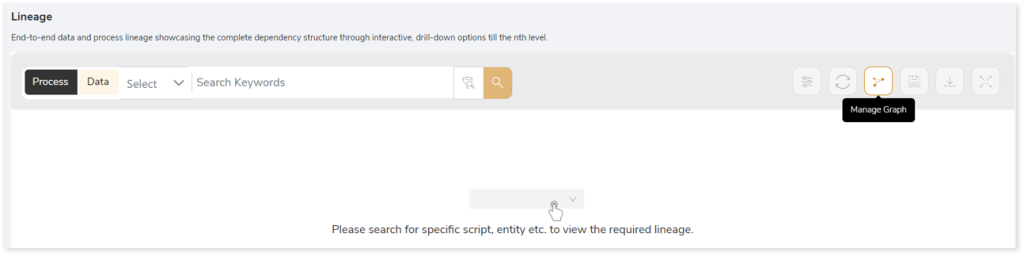
To view the required lineage:
- Select either the Process or Data tab to enable process or data lineage respectively.
- Enter the keywords in the Search Keywords field you want to search. Else, simply select the entities, files, scripts, etc., from the Search dropdown.
- To generate column-level lineage, turn on the Include Columns toggle (available only in Data Lineage).
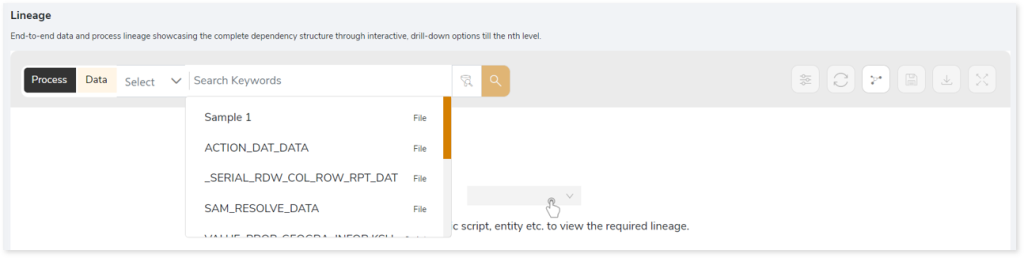
- Click the Search icon to generate the lineage.
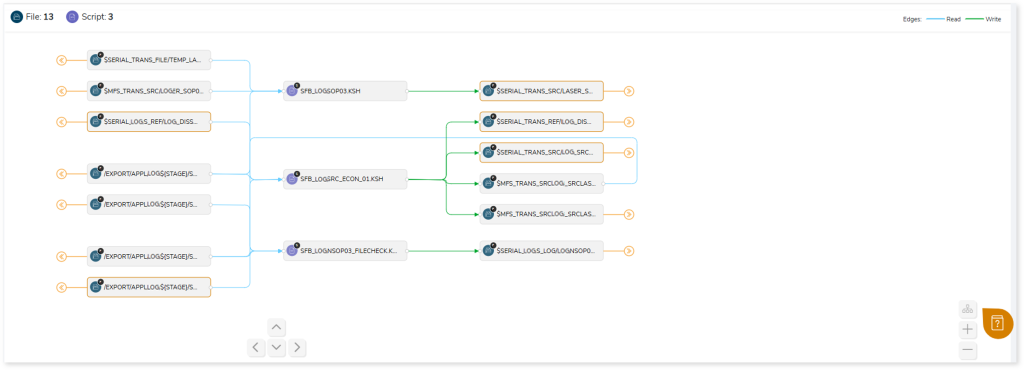
Lineage helps you understand dependencies across processes, tables, and columns:
- Process lineage illustrates the dependencies between two or more processes such as files, scripts, entities, etc.
- Data lineage depicts the table-level dependencies and column-level dependencies–input tables, output tables, and reference tables.
- Column-Level lineage shows granular transformations and updates at the minutest level.
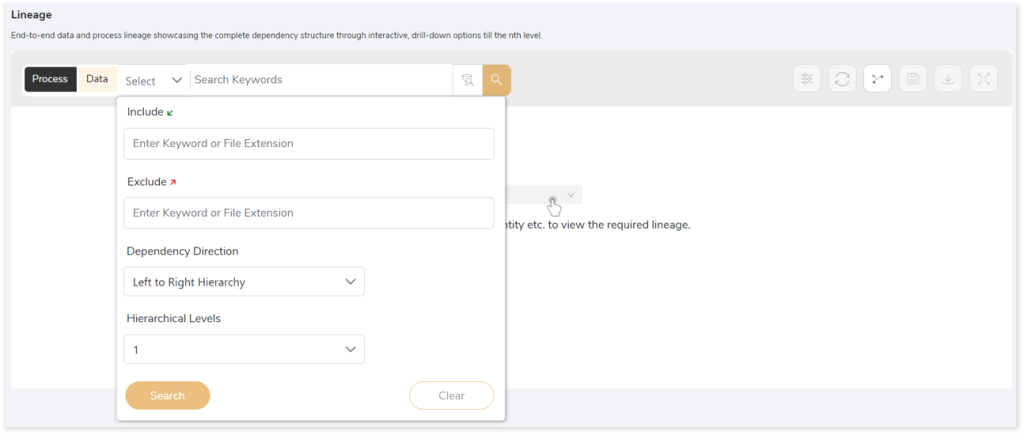
In addition, the filter search icon  allows you to include or exclude particular nodes to obtain the required dependency structure. It helps you quickly narrow down complex dependency graphs to focus on the exact nodes, relationships, or data flows you want to analyze. Instead of navigating through an entire lineage network, you can apply filters based on object names, types, or relationship categories—making it easier to isolate specific tables, or transformation paths. This feature enhances traceability, reduces visual clutter, and enables you to precisely identify upstream or downstream dependencies that are most relevant to your analysis or migration scope.
allows you to include or exclude particular nodes to obtain the required dependency structure. It helps you quickly narrow down complex dependency graphs to focus on the exact nodes, relationships, or data flows you want to analyze. Instead of navigating through an entire lineage network, you can apply filters based on object names, types, or relationship categories—making it easier to isolate specific tables, or transformation paths. This feature enhances traceability, reduces visual clutter, and enables you to precisely identify upstream or downstream dependencies that are most relevant to your analysis or migration scope.
You can also choose the direction of the lineage. By default, the Dependency Direction is Left to Right Hierarchy. This insight is useful to identify and analyze upstream data connections and relationships. You can also choose Right to Left Hierarchy – most useful for how data is getting consumed through the downstream route and which are the participating tables and columns, or Bidirectional dependency direction to visualize both kinds in a single view.
Moreover, you can also increase the Hierarchy Levels to nth level. This again allows great freedom to visualize the end-to-end hierarchy in one go.
Lineage facilitates you visualize how your selected nodes are connected and depend on each other. The nodes and their connecting edges (relationships) help you to understand the overall structure and dependencies.
|
Nodes |
Edges |
 Tables Tables |
 Call Call |
 File File |
 Read Read |
 Job Job |
 Execute Execute |
 Autosys Box Autosys Box |
 Read Read |
 Script Script |
 Others Others |
Manage Lineage
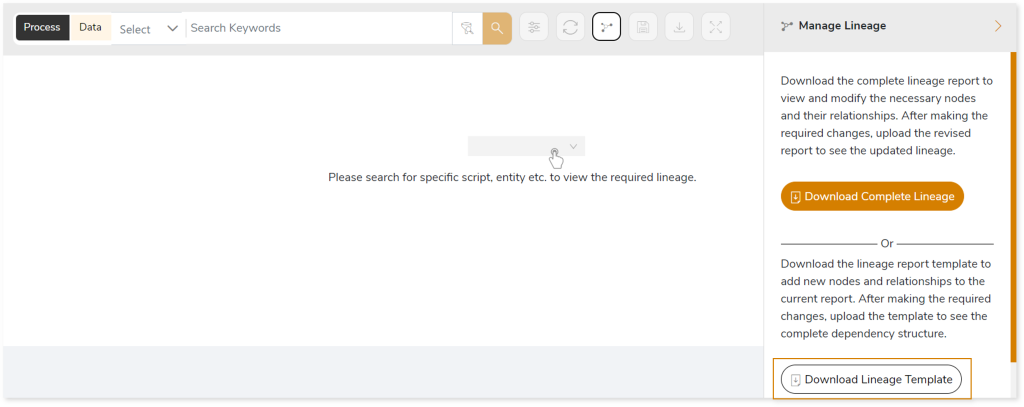
This feature enables you to view and manage your lineage. You can add, modify, or delete nodes and their relationships to generate an accurate representation of the required dependency structure. There are two ways to update the lineage: either using Complete Lineage report or Lineage Template.
Using Complete Lineage report
Follow the below steps to modify the lineage:
- Click the Manage Graph icon.
- Click Download Complete Lineage to update, add, or delete the nodes and their relationships in the current lineage.
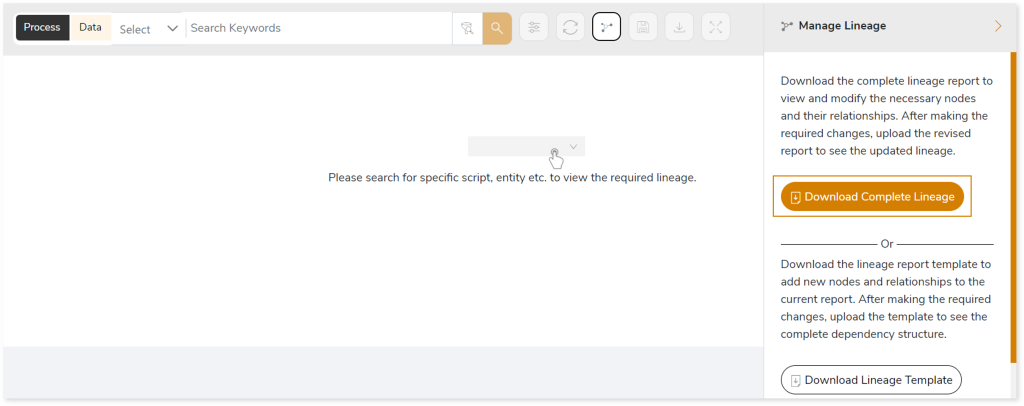
- Once the complete lineage report is downloaded, you can make necessary updates such as updating, deleting or adding the nodes and its relationships.
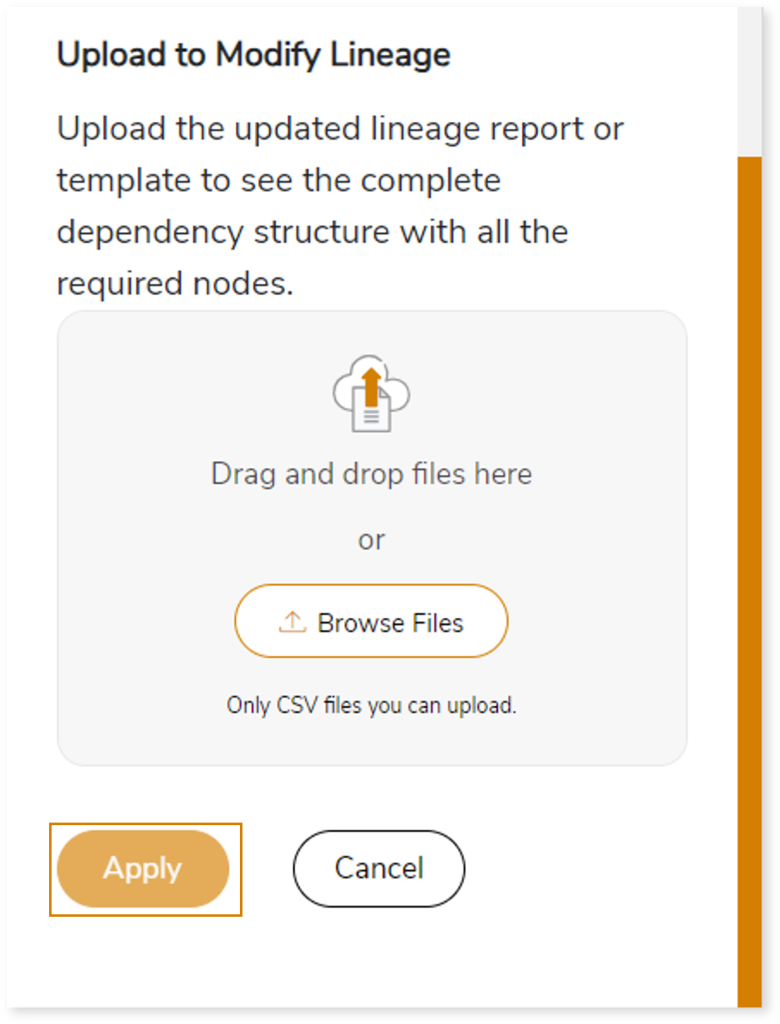
- After making the required changes, upload the updated lineage report in Upload to Modify Lineage.
- Click Apply to incorporate the updates into the dependency structure.
- Generate the required process or data lineage.
Using Lineage Template
Follow the below steps to add new nodes and their relationships to the current lineage report:
- Click the Manage Graph icon.
- Click Download Lineage Template.
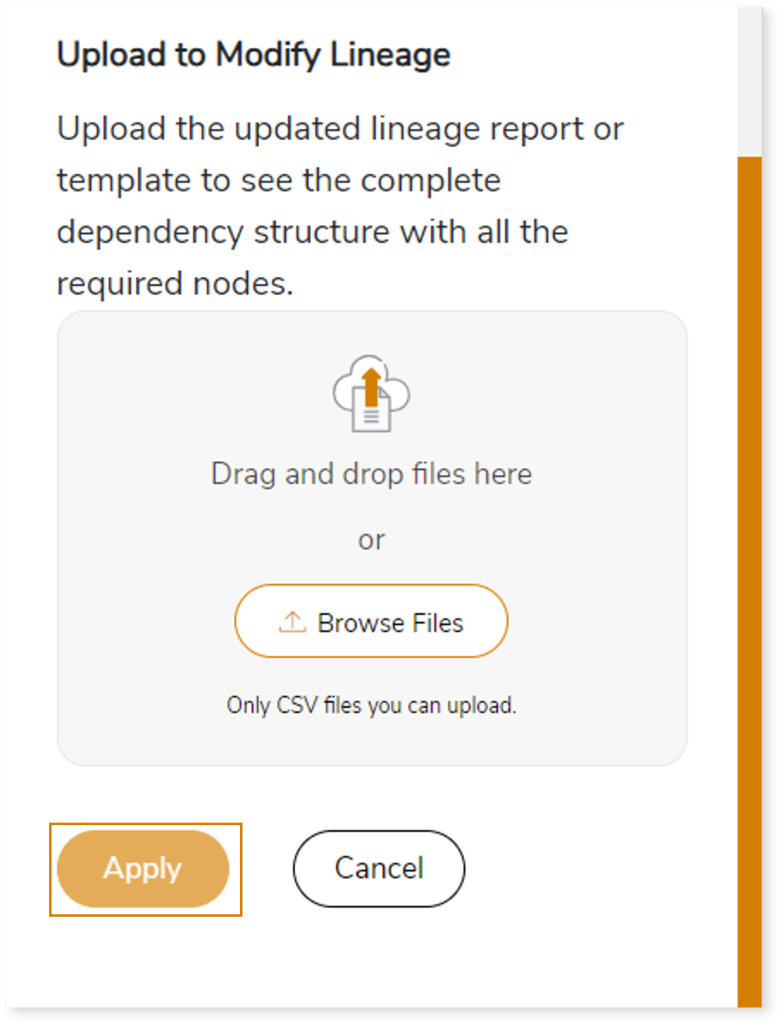
- Once the lineage template is downloaded, you can add new nodes and relationships in the template.
- After making the required changes, upload the template in Upload to Modify Lineage.
- Click Apply to incorporate the updates into the complete dependency structure.
- Generate the required process or data lineage.
You can also apply:
| Feature | Icon | Use |
| Filter |  | Used to filter the lineage. |
| Reload Graph |  | Assists in reloading graphs. |
| Manage Graph |  | To view and manage lineage by adding, modifying, or deleting nodes and their relationships to accurately reflect dependency structures. |
| Save |  | Used to save the lineage. |
| Download |  | Used to download the file. |
| Expand | 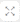 | Used to enlarge the screen. |
Downloadable Reports
Downloadable reports allow you to export detailed assessment reports of your source data which enables you to gain in-depth insights with ease. To access these assessment reports, click Reports.

Types of Reports
In the Reports section, you can see various types of reports such as Insights and Recommendations, Source Inventory Analysis, and Lineage Analysis reports. Each report type offers detailed information allowing you to explore your assessment results.

Insights and Recommendations
This report provides an in-depth insight into the source input files. It contains the final output including the details of queries, complexity, components, and so on.
Here, you can see the abinitio folder along with Abinitio Assessment.xlsx report.

Abinitio Assessment.xlsx: This report provides information about the source inventory including DML files, XFR files, and complexity.
This report contains the following information:
- Report Summary: Provides information about all the generated artifacts.
- Volumetric Info: Presents a summary of the aggregated inventory after analyzing the source files. For instance, it provides total number of files, components, XFRs, and likewise. It also provides file and query level complexity.
- DML Summary: Provides information about internal DML files in the kab files.
- XFR Summary: Provides information about XFR files that contain transformation logic.
- Abinitio Complexity: Provides complexity details of the AbInitio files. It includes statistical and complexity details of components, complex DML files, complex XFR files, and so on.
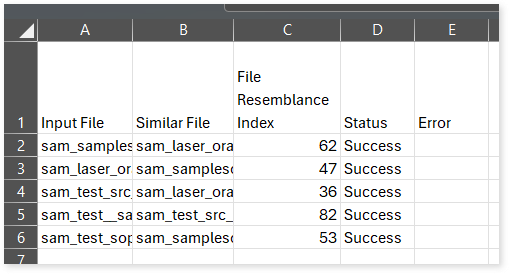
- File Similarity Summary: Provides the file resemblance index by comparing each file with all the other input files. It includes details of each input file, its corresponding similar file, the file resemblance index, and the comparison status. If file comparison succeeds, the Status column shows Success; otherwise, it shows Fail with the corresponding reason in the Error column.
- Invalid Graph: Lists all the invalid file or graph paths along with the reason.
Additional Ab Initio Assessments Reports
To access additional assessment report, open the abinitio folder.
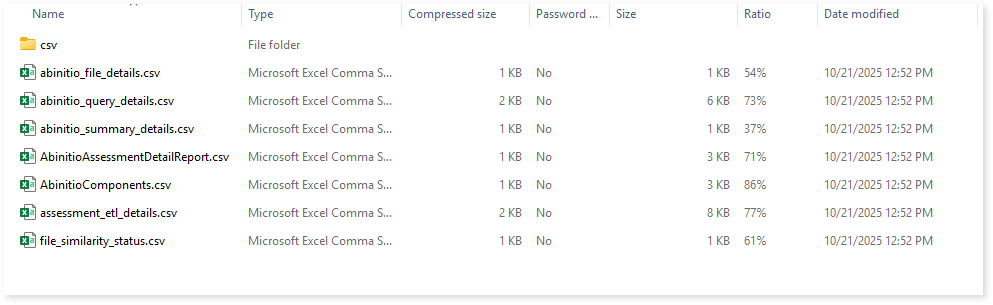
abinitio_file_details.csv: This report provides information about the source files including total number of components, complexity, conversion percentage, etc., of each file.
abinitio_query_details.csv: This report provides information about queries including the used and impacted tables, analyzed status, complexity, and more. If the analyzed status is TRUE, it indicates that the query is analyzed successfully. Conversely, a FALSE status indicates that the query is not analyzed.
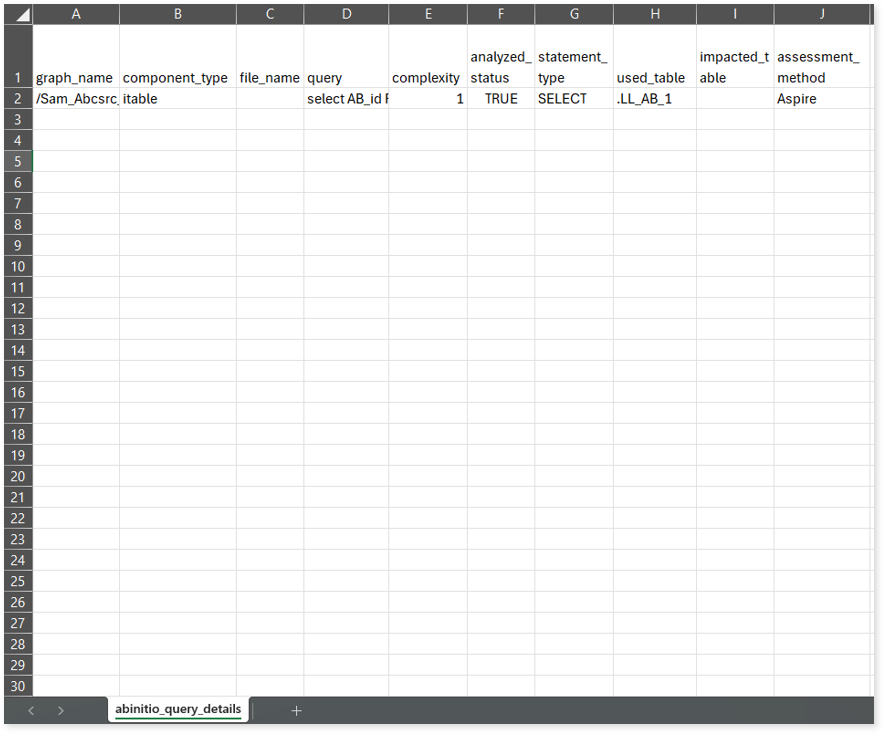
abinitio_summary_details.csv: This report provides a summary of source input files including statistical information such as total number of files, analyzed percentage, components, and more.
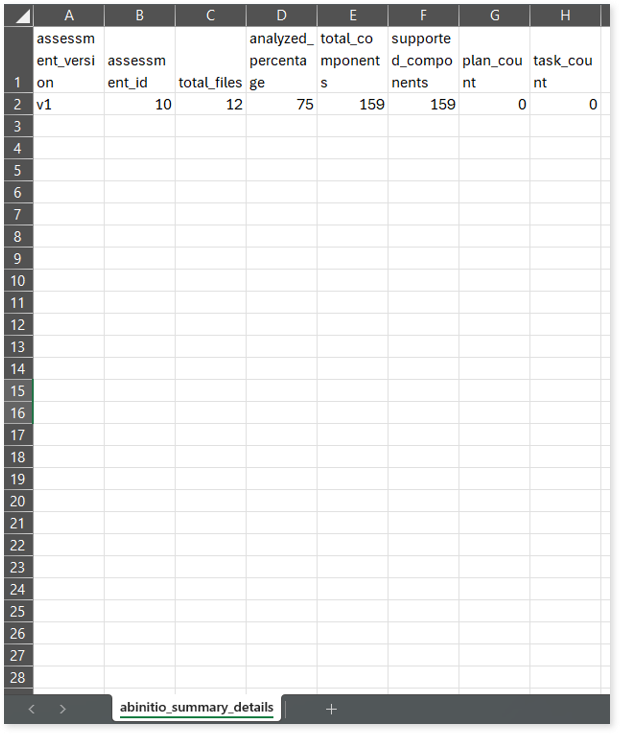
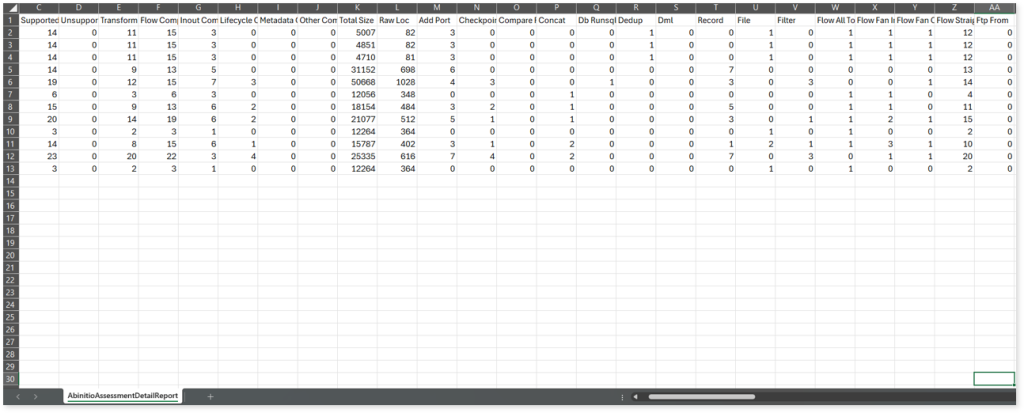
AbinitioAssessmentDetailReport.csv: This report provides detailed insights about the source inventory. It includes information about components, conversion percentage, and more.
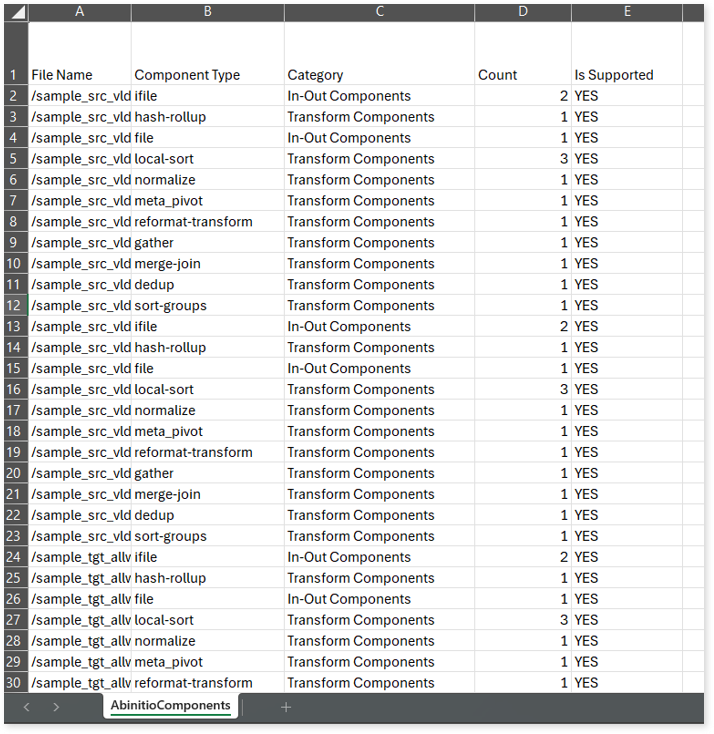
AbinitioComponents.csv: This report provides information about the Ab initio components, including their type, category, count, and whether they are supported.
file_similarity_summary.csv: This report provides the file resemblance index by comparing each file with all the other input files. It includes details of each input file, its corresponding similar file, the file resemblance index, and the comparison status. If file comparison succeeds, the Status column shows Success; otherwise, it shows Fail with the corresponding reason in the Error column.
Browse through the csv folder to access the Updated Complexity.csv file.
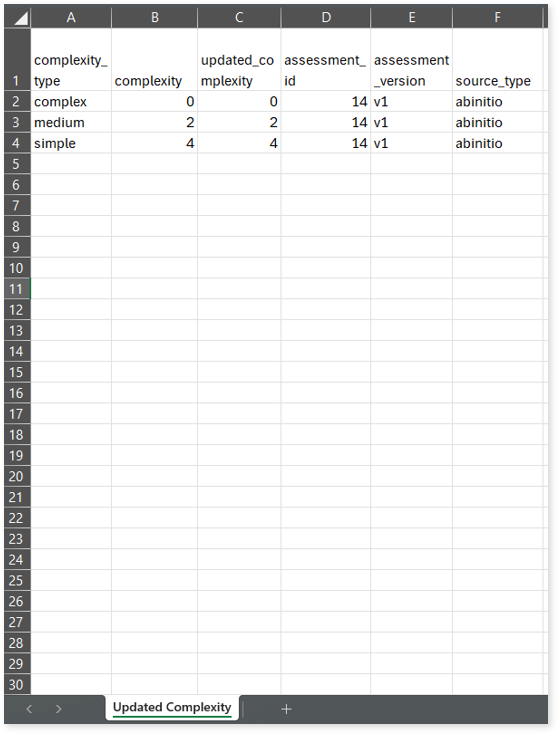
Updated Complexity.csv: This report provides information about the updated complexity of the Ab Initio ETL graphs. During the configuration of the Ab Initio Assessment, you can redefine the Complexity Distribution field to transfer the complexity of queries or files from a higher level to a lower level. This updated complexity is reflected in this report.
Source Inventory Analysis
It is an intermediate report which helps to debug failures or calculate the final report. It includes all the generated CSV reports.

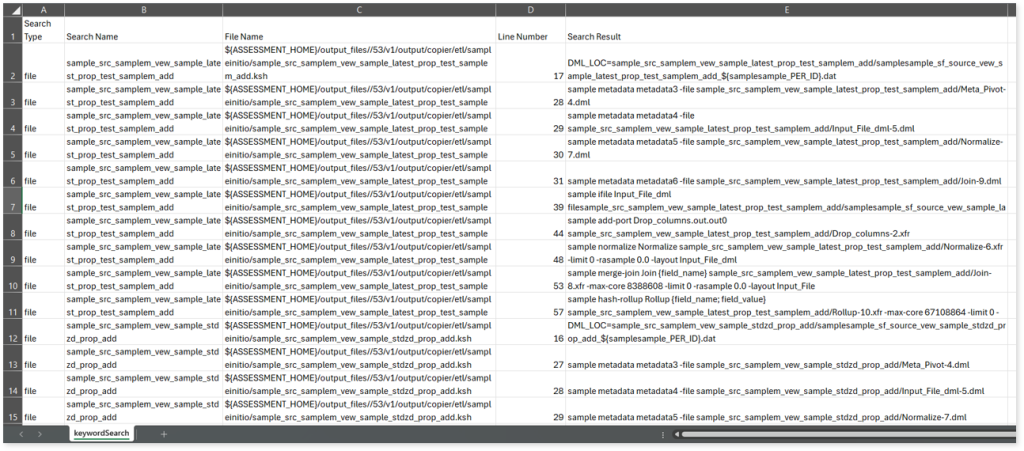
keywordSearch.csv: This report provides keyword search results for all files identified in the uploaded source files. It includes details such as the search type, the file that contains the search keyword, the line number where it occurs, and other related information for each keyword.
This report helps to identify where specific file names appear across the uploaded source files. The system searches for each file name across all other uploaded source files, excluding the same file.
For example, if there are three files—File 1, File 2, and File 3—the system searches for occurrences of File 1 only in File 2 and File 3, excluding File 1 itself.
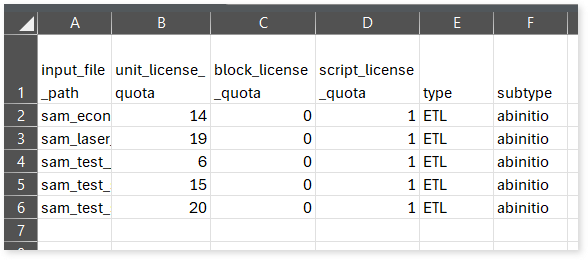
license_quota_info.csv: This report provides information about the anticipated license quota deduction when executing a transformation pipeline or notebook using the same source input file that was used during the assessment. It includes details about the expected quota consumption for units, blocks, and scripts.
Lineage_Raw.xlsx: This report provides complete dependency details for all nodes. It provides an end-to-end data, process, and data model lineage that helps to identify the complete dependency structure and the data flow.
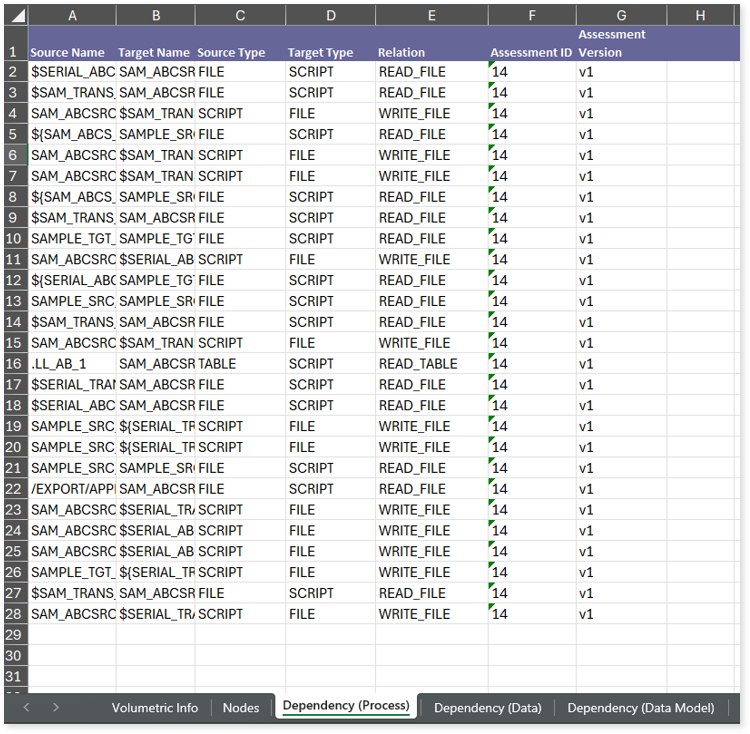
This report contains the following information:
- Volumetric Info (Summary): Provides volumetric information about the artifact types such as script, and file.
- Nodes: Lists all the source and target nodes along with their type. Each node represents a data object in the lineage—such as a file, script, etc.—making it easier to trace how data is consumed, transformed, and processed across the data flow.
- Dependency (Process): Provides information about the process lineage. It offers detailed visibility into interdependencies between processes—such as files, scripts—helping you understand how they are connected within the data flow.
- Dependency (Data): Provides information about the data lineage. It captures detailed table-level—including input tables, output tables, and reference tables—offering end-to-end visibility into how data flows and transforms across the workflow.
- Dependency (Data Model): Provides dependency details about the data models. It highlights the end-to-end relationships and dependencies between model elements, helping you understand structure and trace linkages.
To access various outputs such as abinitio_dml_details.csv, abinitio_external_files.csv, abinitio_xfr_details.csv, AbinitioComponentMetadataReport.csv, AbinitioComponents.csv, AbinitioFileAvailabilityReport.csv, and more, navigate through the etl > abinitio folders.
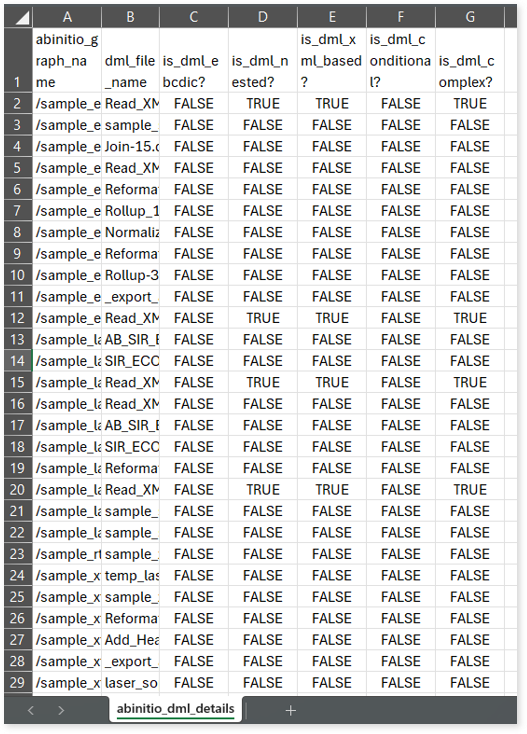
abinitio_dml_details.csv: This report provides information about Ab initio graphs along with associated DML files, including whether DML files use EBCDIC, EML-based, conditional, and more.
abinitio_external_files.csv: This report provides information about external files.
abinitio_xfr_details.csv: This report provides information about XFR files.
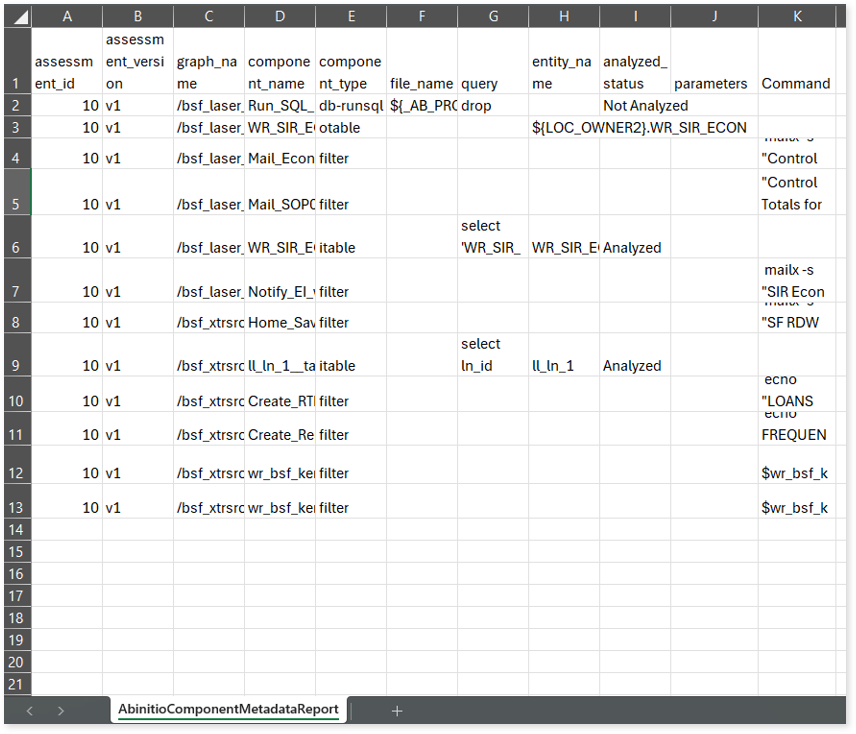
AbinitioComponentMetadataReport.csv: This report provides information about the Component Metadata including component types, queries, entities, and more.
AbinitioComponents.csv: This report provides information about the Ab initio components, including their type, category, count, and whether they are supported.
AbinitioFileAvailabilityReport.csv: This report provides information about the availability of each file.
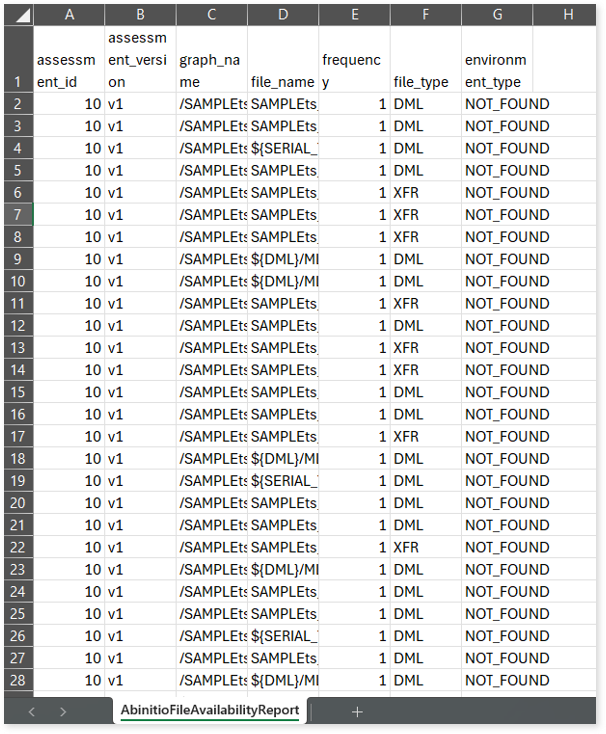
assessment_unparsed_files.csv: This report lists all the unparsed Ab Initio files along with the reason for parsing failure.

file_similarity_status.csv: This report provides the file resemblance index by comparing each file with all the other input files. It includes details of each input file, its corresponding similar file, the file resemblance index, and the comparison status. If file comparison succeeds, the Status column shows Success; otherwise, it shows Fail with the corresponding reason in the Error column.
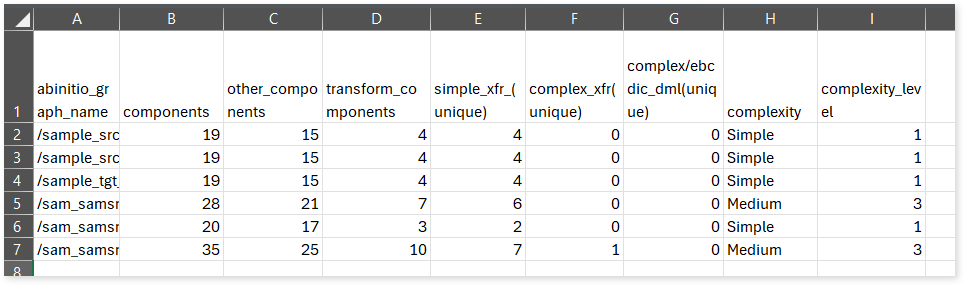
graph_summary_details: This report provides a summary of Ab Initio graph, including the number of components, transformation components, complexity, and more.
invalid_query.csv: This report lists all the invalid queries.
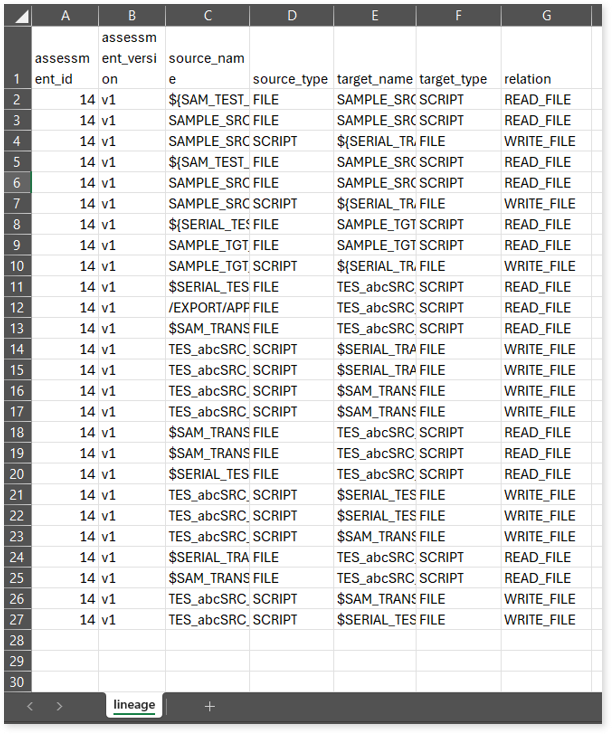
lineage.csv: This report provides source to target lineage details including their types, relationships, and more.
Lineage Analysis
This section provides lineage-related reports, including entity_link.csv, entity_report.csv, entity_summary.csv, link.csv, script_report.csv reports.
entity_links.csv: This report provides information about how views are connected to entities or tables and how these links extend across multiple levels. Level 1 shows the immediate table to which a view is linked. If that table is further connected to another entity, the next connection appears in Level 2, and so on.

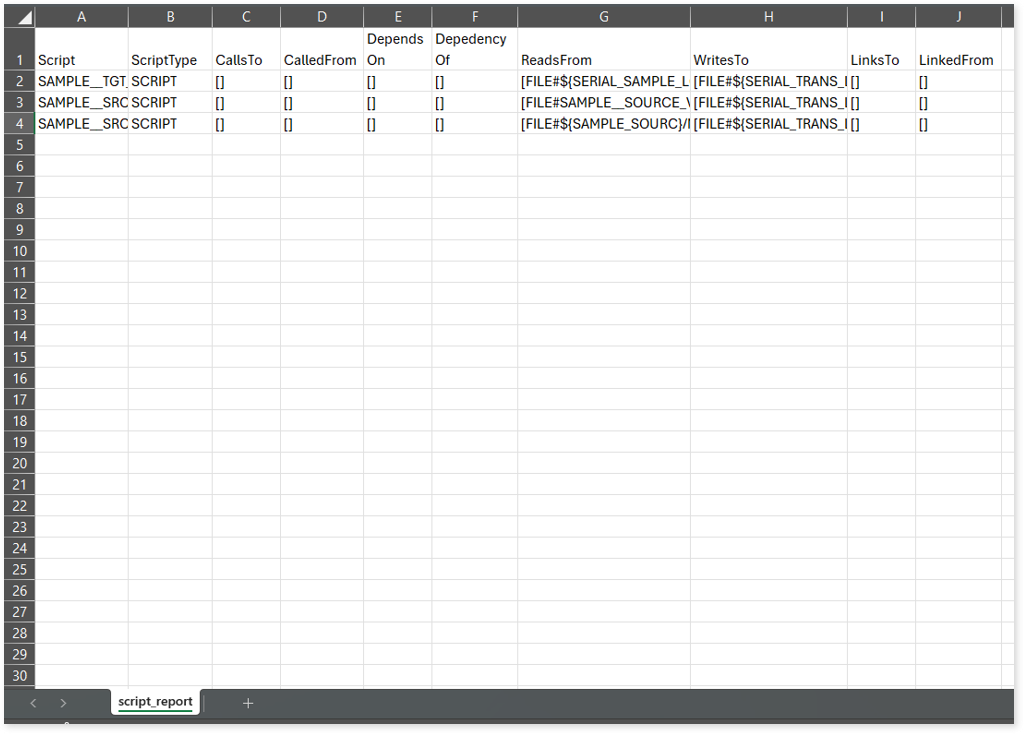
entity_report.csv: This report provides detailed lineage information for each entity within the uploaded source files. It provides a comprehensive list of all entities along with their respective types, identifies the processes or scripts that read from or write to each entity, and includes other dependency details.
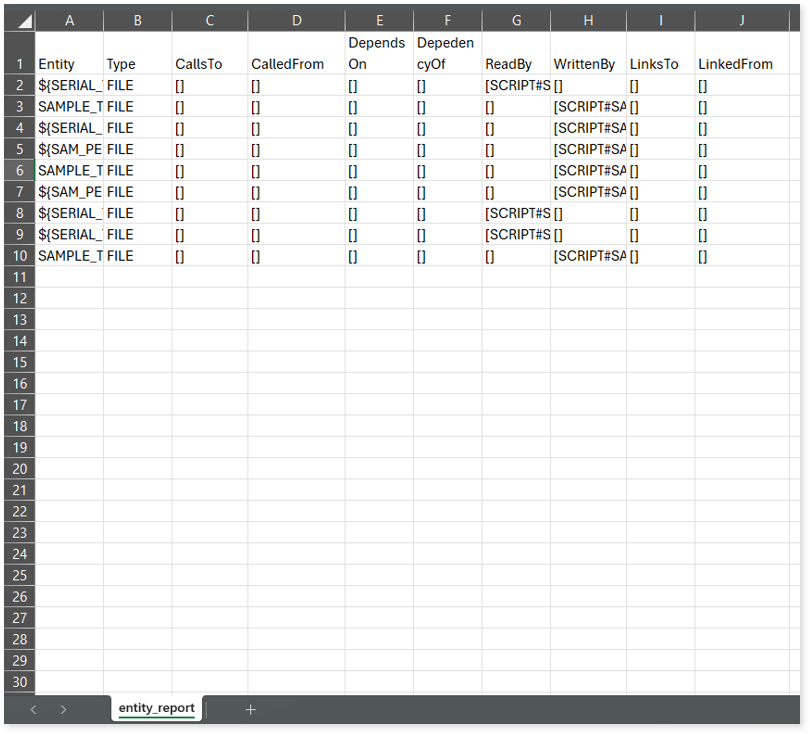
entity_summary.csv: This report provides a list of entities from uploaded source files, indicating where they appear (e.g., script) and the operations performed on them—Read, Write, or ReadWrite.
link.csv: This report provides information about entities linked to each view.
script_report.csv: This report provides detailed lineage information for each script. It lists all scripts along with their type, specifies the processes, entities, or scripts from which each script reads data and those to which it writes, as well as other dependency details.