Configuring SAS
To configure the SAS analytics conversion stage, follow the below steps:
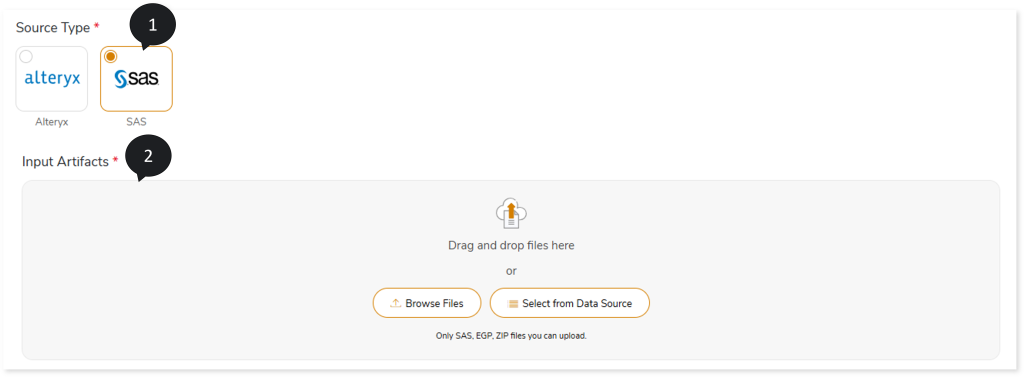
- In Source Type, select the source data source as SAS.
- In Input Artifacts, upload the SAS scripts.
- In Target Type, select the preferred target type, such as AWS Glue Notebook, Databricks Notebook, Snowflake, or Spark.
- If the selected target is Spark, click Data Configuration to proceed. For other targets, click Save.

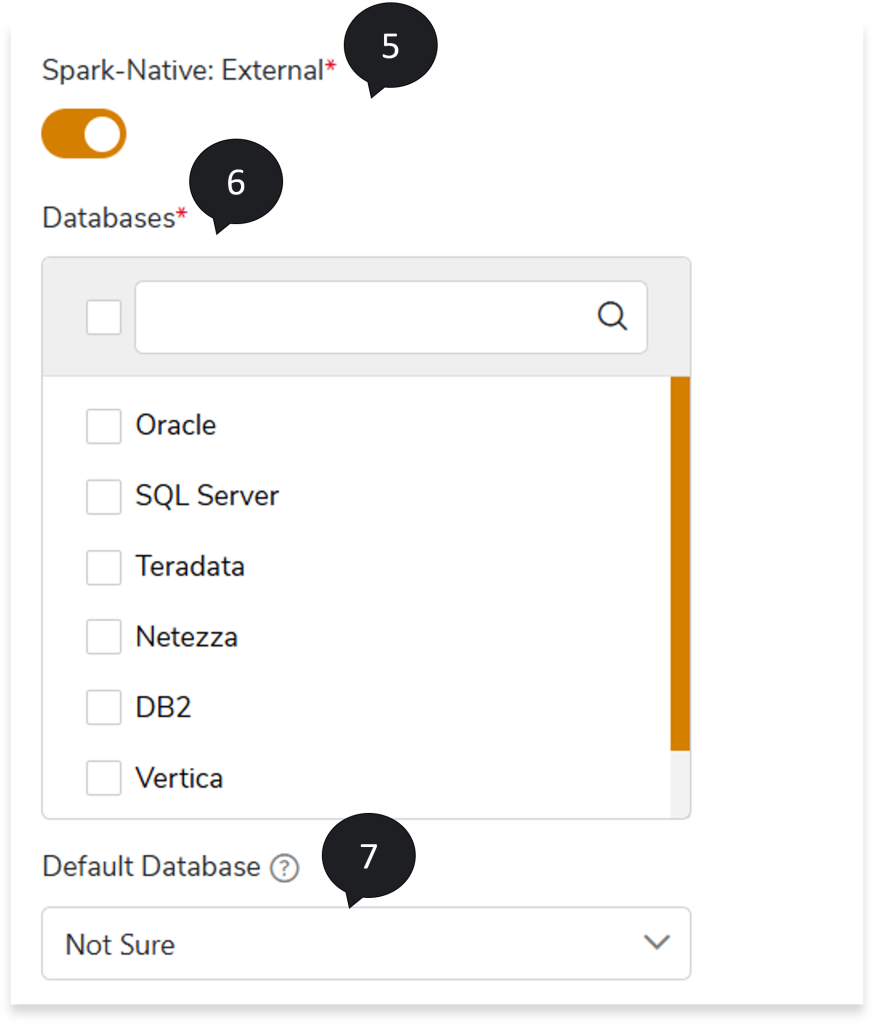
- Enable Spark-Native: External toggle to fetch input data from an external source such as Oracle, Netezza, Teradata, etc., and process that data in Spark, and then move the processed or output data to an external target. For instance, if the source input file contains data from any external source like Oracle, you need to select Oracle as the Databases to establish the database connection and load the input data. Then data is processed in Spark, and finally the processed or output data gets stored at an external target (Oracle). However, if you select Oracle as the Databases but the source input file contains data from an external source other than Oracle, such as Teradata, then by default, it will run on Spark.
- In Databases, select the database you want to connect to. This establishes the database connection to load data from external sources like Oracle, Teradata, etc. If the database is selected, the converted code will have connection parameters (in the output artifacts) related to the database. If the database is not selected, you need to add the database connection details manually to the parameter file to execute the dataset; otherwise, by default, it executes on Spark.
- In Default Database, select appropriate default database (Teradata, Netezza, Oracle, etc.) for queries where the database type is not defined in the uploaded artifacts. Selecting Not Sure will only convert queries whose database type is available.
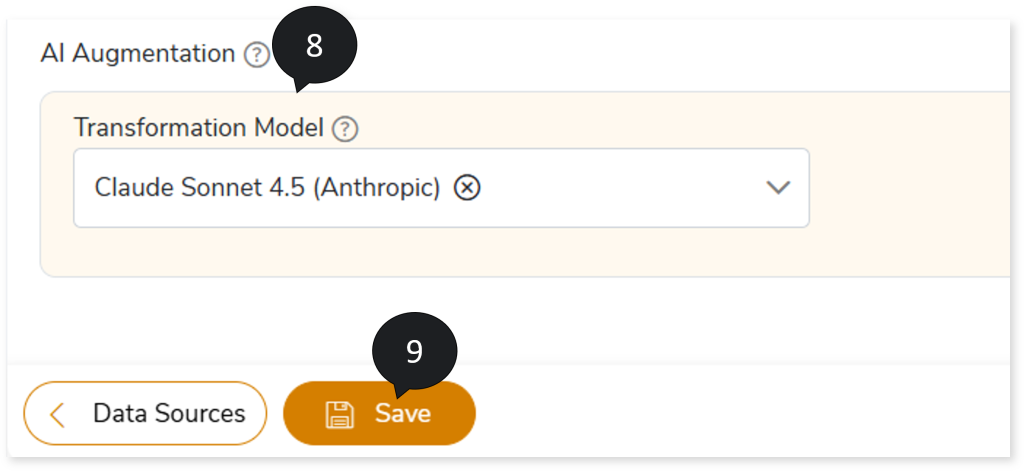
- In AI Augmentation, select the preferred Transformation Model to convert SAS code that requires augmented transformation and optimize it for accuracy and performance, including agentic AI‑led conversion of SAS scripts—particularly data steps and PROC SQLs.
- In Transformation Model, select the preferred Transformation model to convert SAS code that are not handled by the default LeapLogic Core transformation engine to the target equivalent.
- Click Save to update the changes.
- Click
 to provide a preferred pipeline name.
to provide a preferred pipeline name.
- Click
 to execute the pipeline. Clicking (Execute) navigates you to the listing page which shows your pipeline status as Running state. It changes its state to Success when it is completed successfully.
to execute the pipeline. Clicking (Execute) navigates you to the listing page which shows your pipeline status as Running state. It changes its state to Success when it is completed successfully.
- Click pipeline card to see report.
To view the SAS Transformation Stage report, visit SAS Transformation Report.