Configuring Data Load Stage
This node is designed to ingest a CSV file kept at a UFS location, directly into Hive tables. You can also overwrite existing data if needed.
In This Topic:
Overview
In this section, you can customize Data Load name and add a suitable description that describes the purpose and scope of the stage. By default, Data Load is provided in the Name field.
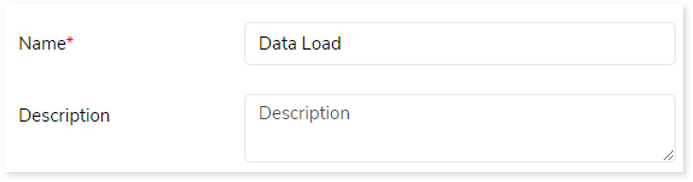
Transform
The input to Data Load stage is a CSV file placed at a UFS location and the target is Hive table to which you need to load the CSV file.
To configure the Data Load stage, follow the below steps:
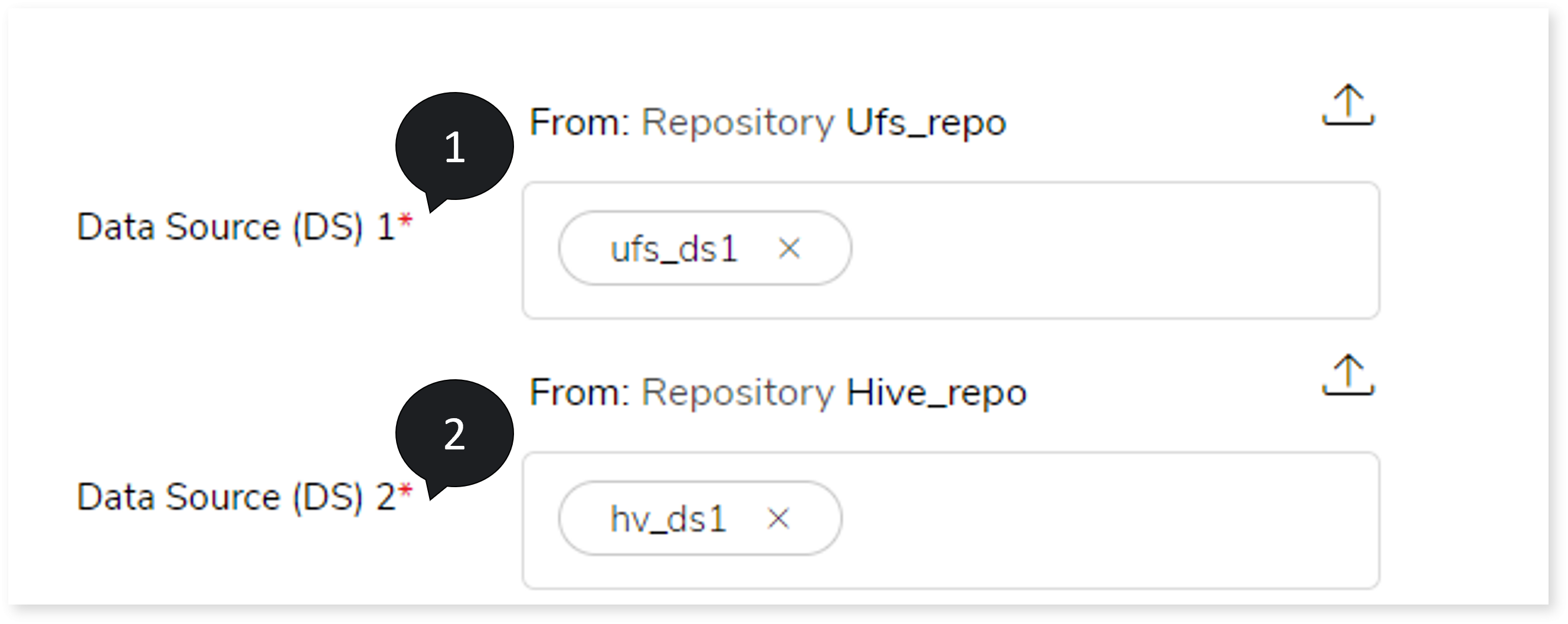
- To upload the data source from where you need to load the data, follow the below steps:
- Click Data Source (DS)1.
- Choose repository.
- Select data source.
- Click
 to save the source data source.
to save the source data source.
- To upload the Hive data source to which you need to ingest the data, follow the below steps:
- Click Data Source (DS)2.
- Choose repository.
- Select data source.
- Click to save the Hive data source.
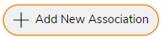
- In Field Delimeter, select the field separator that delimits the information across the columns in the input file, such as “,”, “|”, “#”, “!”, “@”, “$” or ” “.
- In Blank Column Value, provide a value to replace all the blank rows while ingesting data into the target table, for example, null.
- In Escaped By, provide a delimiter to exclude the records before they are detected.
- If the uploaded CSV file contains a header for the columns, turn on the Includes Header toggle.
- Click
 to associate target entities with source files.
to associate target entities with source files.
- You can load data from CSV file into the target entities via any of the following methods:
- Existing target Entity: Ingest data into an existing Hive table.
- New target entity: Create a new target entity and load data into it.
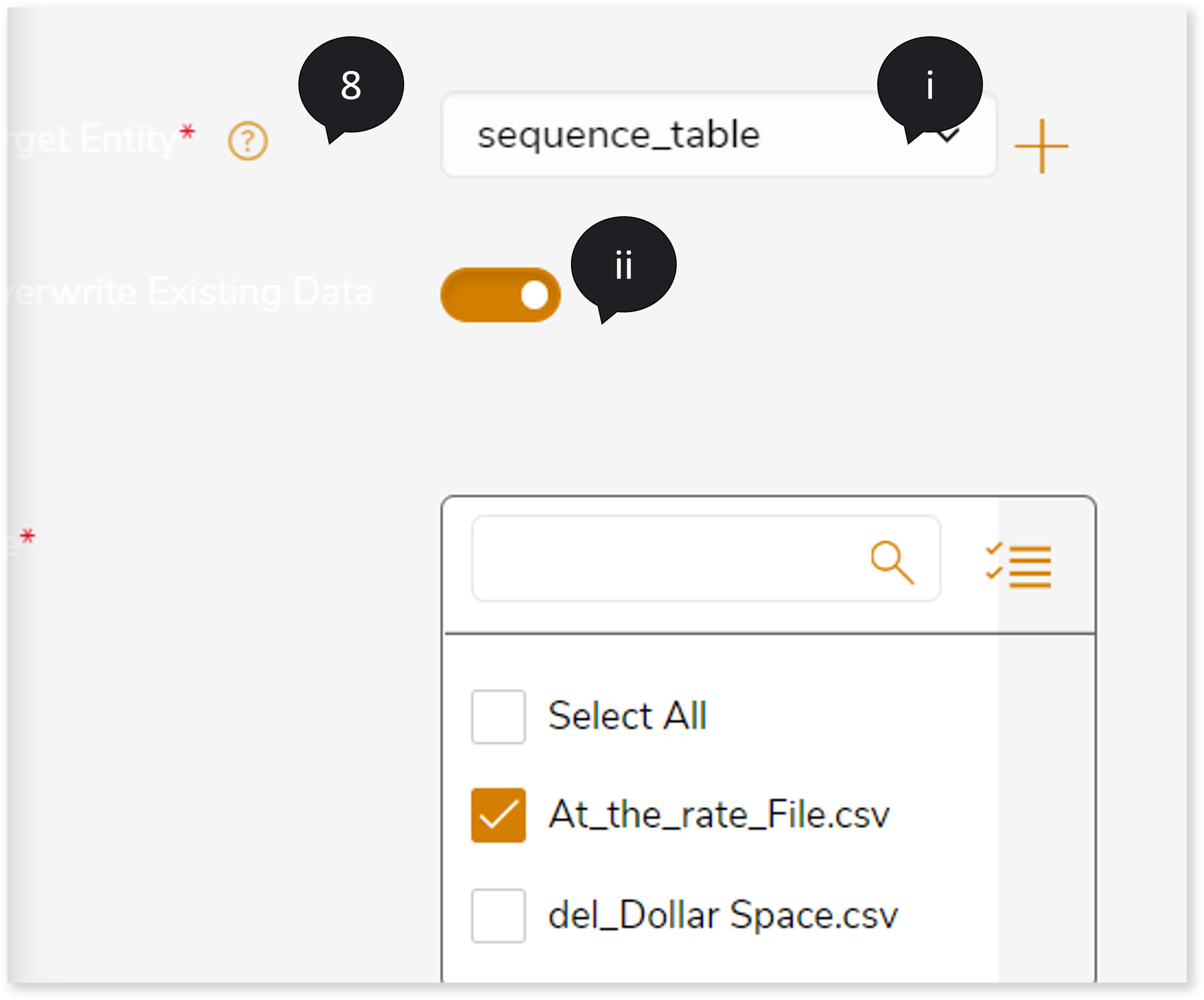
- If you need to insert the files into an existing target entity, follow the below steps:
- In Target Entity, select entities to map the selected entities with the source files in the source data store. Ensure each entity has the appropriate mapping/association files.
- To overwrites the existing data in the target Hive tables, turn on Overwrite Existing Data toggle.
To map CSV files to the target table, select the entities from the table list.
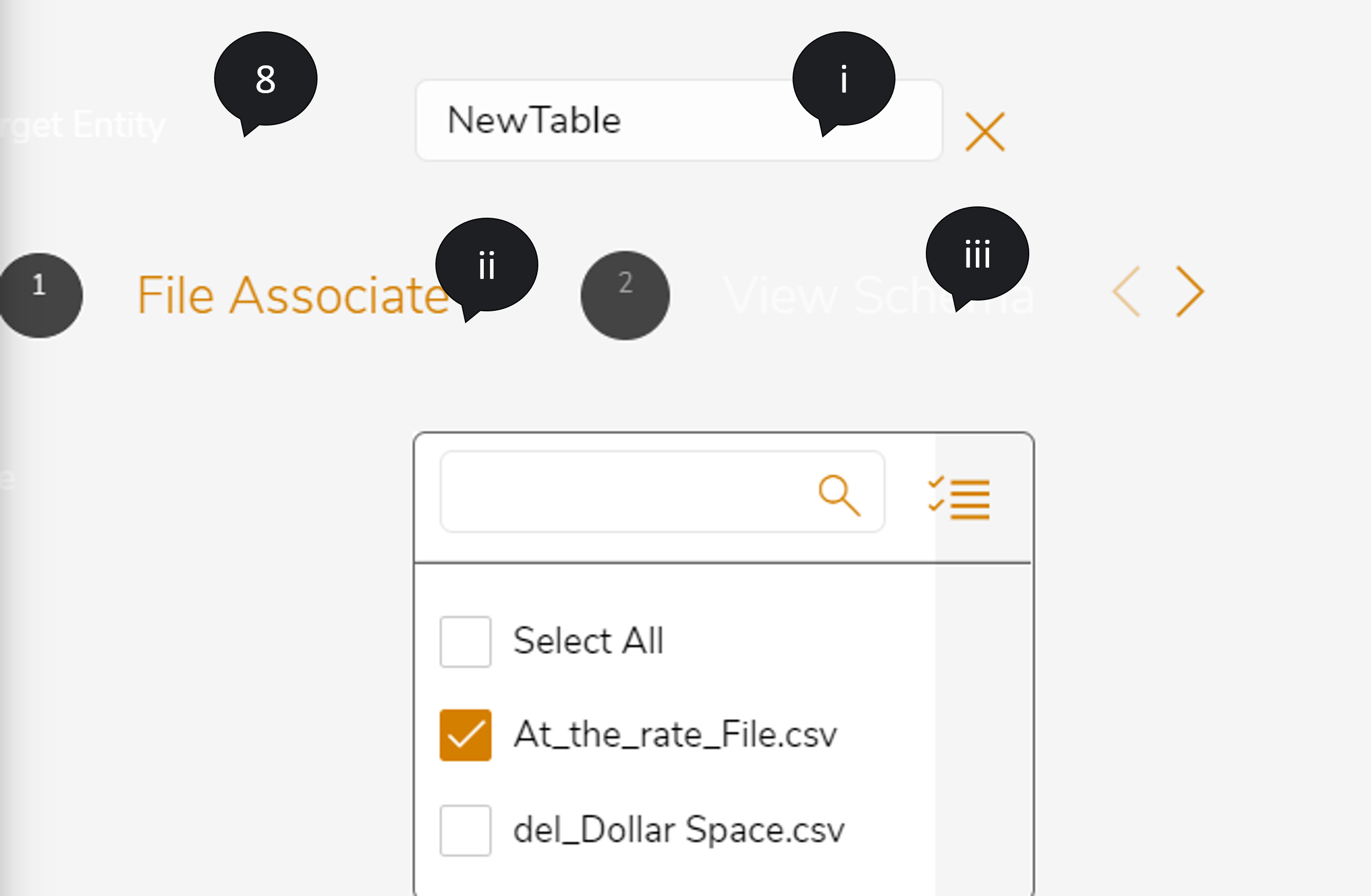
- If you need to insert the source files into a new target entity, follow the steps below:
- Click
 to create new target entity. In Target Entity, enter the preferred name.
to create new target entity. In Target Entity, enter the preferred name. - In File Associate, select the files that you need to associate.
- Select View Schema and then choose the files that need to map to the target entity.
- Click
 to apply the configuration.
to apply the configuration.
- Click Save to save the Data Load stage. When a Data Load stage is successfully saved, the system displays an alerting snackbar pop-up to notify the success message.

- Click
 to execute the pipeline. Clicking (Execute) navigates you to the pipeline listing page which shows your pipeline status as Running state. It changes its state to Success when it is completed successfully.
to execute the pipeline. Clicking (Execute) navigates you to the pipeline listing page which shows your pipeline status as Running state. It changes its state to Success when it is completed successfully. - Click on your pipeline card to see reports.
To view the Data Load Stage report, visit Data Load Report.
Output
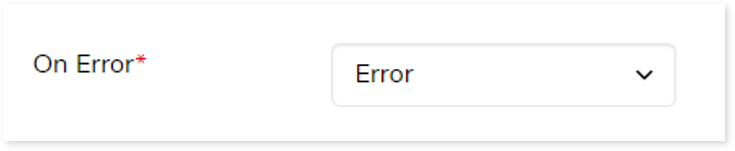
In this section, you can configure the output of the Data Load stage for navigating to the next stage in case of an error. By default, the Output configuration is set to Error whenever the system encounters an error, or that can be configured to Continue, Stop, or Pause as required.
Next:
Configuring Multi Algo Stage