Designing Pipeline
This topic describes how to design and manage a pipeline.
Pipeline is a drag and drop based mechanism through which you can perform the batch transformation of legacy workloads to modern data architecture. It contains a transformation library that has transformations or stages for every unique operation. These transformations are repeatable, verifiable, and user configurable.
You can either design an integrated pipeline or design the stages independently (standalone) and then configure them. For instance, the Migration stage can be created individually, allowing you to migrate data from a data source to a target cloud platform like Databricks Delta tables, Redshift, Snowflake, and so on.
In an integrated pipeline, stages are interconnected with one another to form a pipe-like structure (see below figure) where the output of each stage acts as the input for the next stage. Pipeline design arranges the workload transformation process sequentially.
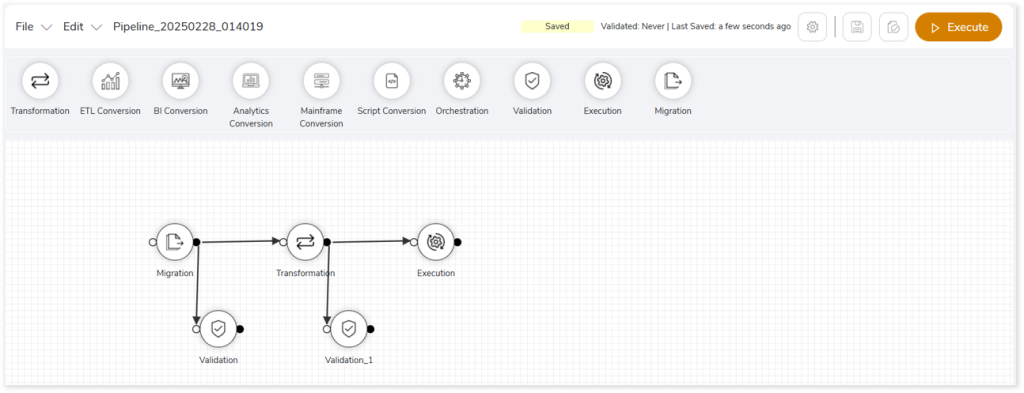
The figure above is an example of an integrated pipeline where all the stages are connected. Here, the source data is uploaded from the metadata repository to the Migration stage and the output of the Migration stage is the input for the Transformation and Validation (Data Validation) stages, where the metadata reference is automatically consumed. Similarly, the output of the Transformation stage is the input for the Validation_1 (Query Validation) and Execution stages.
As designed, the data flow follows the pipeline. You can’t execute the Execution stage as the initial step because the output of the Transformation stage is the input for the Execution stage. However, if you already have the output of the transformation stage downloaded (let’s say), then you may like to upload it in the Execution stage and execute it individually.
Next Topics: